Understanding Whisper: A Comprehensive Guide to OpenAI’s Speech Recognition Model

Eric King
Author
Introduction
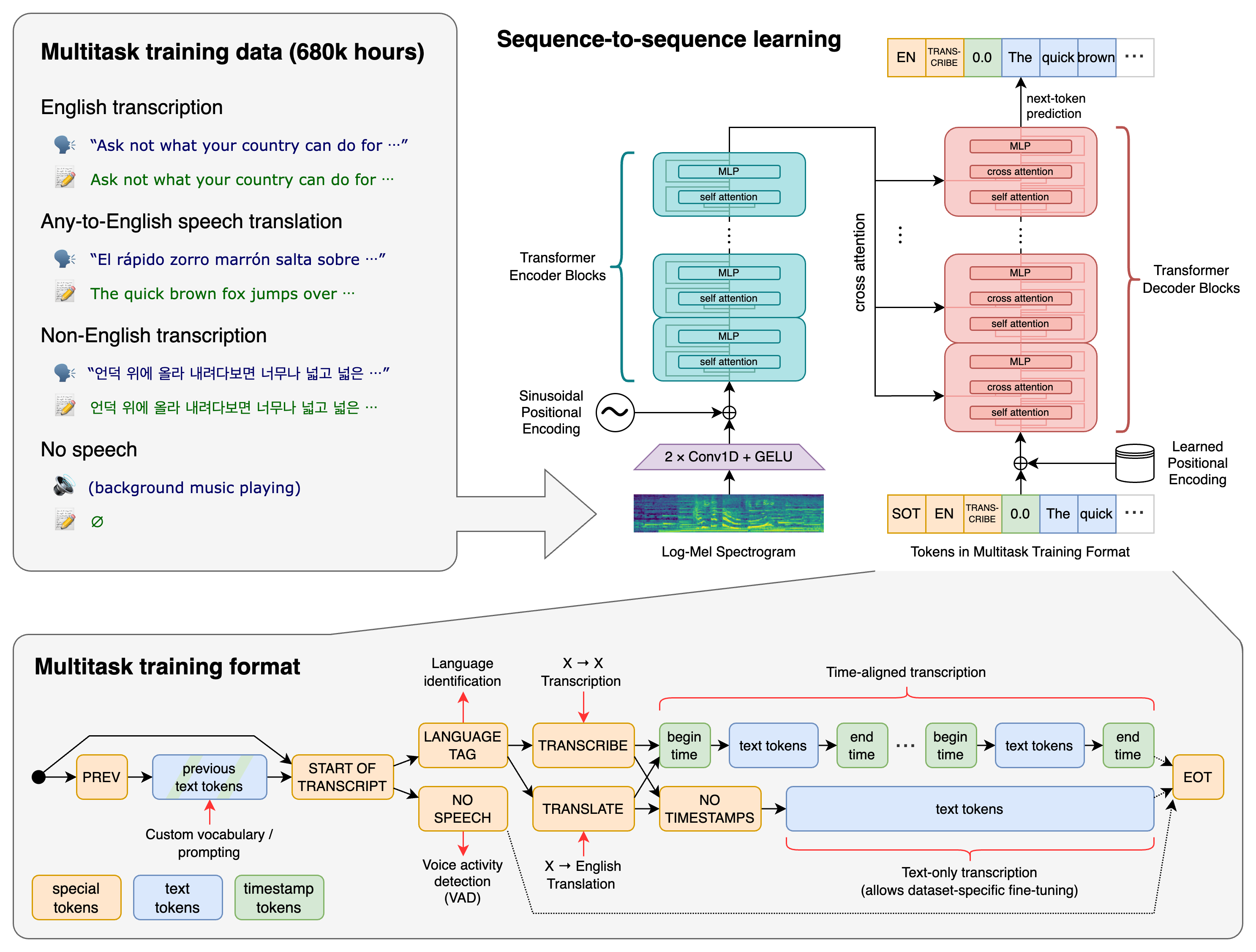
OpenAI’s Whisper is an advanced automatic speech recognition (ASR) model designed to convert spoken audio into accurate, readable text. Released as an open-source project, Whisper has quickly become one of the most widely adopted transcription technologies due to its multilingual capabilities, robustness to noise, and flexibility across real-world scenarios.
This article gives you a clear, SEO-friendly overview of how Whisper works, what makes it unique, its strengths and limitations, and how it compares to other major ASR models in the industry.
What Is Whisper?
Whisper is a deep-learning ASR system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. Its training includes diverse accents, noise conditions, and audio qualities—making it far more robust than many conventional speech recognition models.
Key tasks Whisper supports:
- Speech-to-text transcription
- Speech translation (audio → English text)
- Language identification
- Timestamp generation
- Multilingual transcription
Because Whisper is open source, developers can run it locally, fine-tune workflows, or integrate it into applications without relying on third-party APIs.
Key Features of Whisper
1. Multilingual Speech Recognition
Whisper supports nearly 100 languages, making it ideal for global applications and diverse user bases.
2. High Noise Robustness
Thanks to large-scale training data, Whisper handles:
- Background noise
- Overlapping speech
- Reverberations
- Low-quality microphones
This makes it suitable for real-world audio such as meetings, interviews, and mobile recordings.
3. Word-Level Timestamps
Whisper (and extensions like WhisperX) can generate accurate timestamps, enabling:
- Subtitle generation
- Podcast segmentation
- Video captioning workflows
4. Translation Capabilities
Whisper can directly translate non-English audio into English text without needing a separate translation model.
5. Fully Open Source
Users can deploy Whisper:
- On-premise servers
- Cloud VMs
- Local desktops with GPU
- Edge devices
Being open source also means full control over cost, privacy, and customization.
Whisper Model Variants
| Model Size | Speed | Accuracy | Use Case |
|---|---|---|---|
| Tiny | Fastest | Lowest | Real-time, mobile devices |
| Base | Very fast | Low-Med | Quick transcripts |
| Small | Balanced | Medium | General tasks |
| Medium | Slower | High | Professional transcription |
| Large | Slowest | Highest | Maximum accuracy, multilingual tasks |
Users typically choose based on computation and accuracy requirements.
Strengths of Whisper
- Highly accurate even in challenging conditions
- Handles accents and dialects better than many commercial ASR models
- Multilingual support out of the box
- Open source (no vendor lock-in, customizable)
- Timestamp and segmentation capabilities
Limitations of Whisper
- Requires significant GPU resources for faster speeds
- Large models can be slow on CPU
- May hallucinate small non-speech text in noisy audio
- Not optimized for structured speech tasks (e.g., punctuation rules in specific languages)
For many users, these limitations are addressed through optimized forks like Faster-Whisper, WhisperX, or GPU quantization.
Whisper vs. Other ASR Models (Competitor Comparison)
Below is an SEO-friendly comparison between Whisper and other well-known ASR systems:
ASR Competitor Comparison Table
| Feature / Model | OpenAI Whisper | Google Speech-to-Text | Amazon Transcribe | Microsoft Azure STT | Deepgram |
|---|---|---|---|---|---|
| Open Source | Yes | No | No | No | Partial (SDK only) |
| Multilingual | Excellent | Good | Medium | Good | Medium |
| Noise Robustness | Very strong | Moderate | Medium | Medium | Strong |
| Timestamps | Yes | Yes | Yes | Yes | Yes |
| Real-Time Support | Limited (depends on hardware) | Yes | Yes | Yes | Yes |
| Cost | Free (self-hosted) | Paid | Paid | Paid | Paid |
| Customization | Full (open source) | Limited | Limited | Limited | Medium |
| Accuracy | High | High | High | High | High |
Summary:
Whisper stands out with its openness, cost advantages, and robustness to noise. Cloud ASR services excel in real-time low-latency scenarios, but Whisper provides better flexibility and privacy.
Popular Extensions of Whisper
1. Faster-Whisper
An optimized implementation using CTranslate2. Benefits:
- 2–4× faster inference
- Lower memory usage
- Supports quantization (int8/int16)
Ideal for production servers.
2. WhisperX
Extends Whisper with:
- Word-level alignment
- More accurate timestamps
- Speaker diarization support (via Pyannote)
Perfect for subtitles, podcasts, and media transcription.
3. Distil-Whisper
A distilled, smaller, faster version with minimal accuracy loss.
When Should You Use Whisper?
Whisper is ideal if you need:
- High-accuracy transcription
- Multilingual audio handling
- Privacy-focused deployments
- Customizable pipelines
- Cost-effective large-scale ASR
- Offline or on-device transcription
If latency is your top priority, cloud ASR may still be better.
Conclusion
Whisper represents one of the most important advancements in open-source speech recognition. Its strong performance, multilingual capabilities, and flexibility make it a powerful tool for developers, researchers, and businesses looking to build transcription or translation applications.
With ongoing community innovation—such as WhisperX and Faster-Whisper—the Whisper ecosystem continues to grow, making it an excellent choice for modern ASR workflows.

