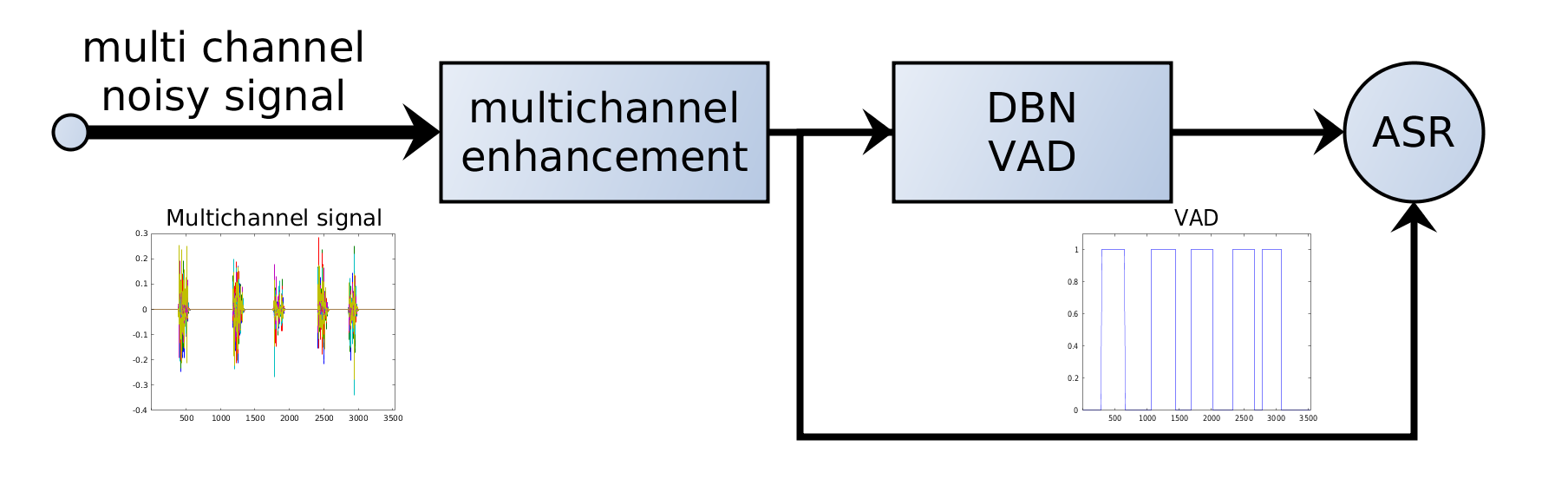
Sprachaktivitätserkennung (VAD)

Eric King
Author
Sprachaktivitätserkennung (Voice Activity Detection, VAD) ist ein Signalverarbeitungsverfahren, mit dem automatisch ermittelt wird, ob ein Audiosegment menschliche Sprache oder Stille/Hintergrundgeräusche enthält. In Sprachsystemen wirkt VAD als Vorverarbeitungsschritt, der Sprachbereiche von Nicht-Sprachbereichen trennt, bevor weitere Schritte wie automatische Spracherkennung (ASR), Sprachübersetzung oder Sprecheranalyse folgen.
1. Was ist Sprachaktivitätserkennung?
Sprachaktivitätserkennung (VAD) ist eine grundlegende Komponente moderner Sprachverarbeitungssysteme. Sie führt eine binäre Klassifikation durch: Für jedes kurze Audiofenster wird entschieden, ob das Fenster Sprache oder Nicht-Sprache (Stille, Rauschen, Musik usw.) enthält.
Das Kernprinzip ist einfach:
Audioframe → VAD-Modell → P(Sprache)
Überschreitet die Wahrscheinlichkeit einen vordefinierten Schwellenwert, wird der Frame als Sprache klassifiziert; andernfalls als Nicht-Sprache.
2. Warum VAD wichtig ist
Rohe Audiosignale enthalten oft:
- Lange Stillephasen
- Hintergrundgeräusche
- Nicht-Sprachlaute (Musik, Klicks, Atmen)
Wird solches Audio direkt an ASR-Modelle gegeben, hat das typischerweise diese Folgen:
- Unnötiger Rechenaufwand bei der Verarbeitung von Stille und Rauschen
- Geringere Erkennungsgenauigkeit durch Rauschstörungen
- Instabile Segmentierung und Zeichensetzungsfehler
- Höhere Verarbeitungskosten durch unnötige Berechnungen
Durch Entfernen von Nicht-Sprachsegmenten verbessert VAD Effizienz und Genauigkeit nachgelagerter Sprachmodelle deutlich.
3. Typische VAD-Verarbeitungskette
Die VAD-Kette umfasst typischerweise:
- Rohaudio →
- Framing (10–30 ms) →
- Merkmalsextraktion →
- Schätzung der Sprachwahrscheinlichkeit →
- Zeitliche Glättung →
- Erzeugung von Sprachsegmenten
3.1 Framing
Das Audiosignal wird in kurze überlappende Fenster (häufig 20 ms) unterteilt, um kurzfristige akustische Eigenschaften zu erfassen. So kann das Audio in handhabbaren Stücken analysiert werden, während Überlappung die zeitliche Information erhält.
3.2 Merkmalsextraktion
Häufige Merkmale für VAD sind:
- Kurzzeitenergie – misst die Signalleistung
- Nulldurchgangsrate – Hinweis auf den Frequenzgehalt
- Spektrale Entropie – misst Zufälligkeit im Frequenzbereich
- Log-Mel-Filterbänke – in neuronalen VADs für bessere Darstellung
Diese Merkmale helfen, Sprache von Nicht-Sprache anhand unterschiedlicher akustischer Eigenschaften zu unterscheiden.
3.3 Schätzung der Sprachwahrscheinlichkeit
Ein Modell (regelbasiert oder neuronales Netz) schätzt die Wahrscheinlichkeit, dass jedes Fenster Sprache enthält. Diese Wahrscheinlichkeit wird mit einem Schwellenwert verglichen.
3.4 Zeitliche Glättung
Entscheidungen auf Framenebene werden mit zeitlichen Regeln zu zusammenhängenden Sprachsegmenten verbunden:
- Ein Sprachsegment beginnt, wenn die Sprachwahrscheinlichkeit über dem Schwellenwert für eine Mindestdauer bleibt
- Ein Sprachsegment endet, wenn Stille länger als eine vordefinierte Stilledauer anhält
So wird häufiges Umschalten zwischen Sprache und Stille durch Rauschen oder kurze Pausen vermieden.
4. Von Frames zu Sprachsegmenten
Frameweise VAD-Entscheidungen müssen in zusammenhängende Sprachsegmente umgewandelt werden. Dazu gelten Glättungsregeln:
- Spracheinsetz: Ein Segment beginnt, wenn die Sprachwahrscheinlichkeit über dem Schwellenwert für eine Mindestdauer bleibt
- Sprachende: Ein Segment endet, wenn Stille länger als eine vordefinierte Stilledauer anhält
So wird Zerstückelung durch kurzes Rauschen oder Pausen innerhalb echter Sprache vermieden.
5. Padding und Randanpassung
Um Anfangs und Ende der Sprache nicht abzuschneiden, verwenden VAD-Systeme meist Padding:
- Kleiner Rand (z. B. 100–300 ms) vor und nach erkannten Sprachsegmenten
- Verbessert Natürlichkeit und Erkennungsgenauigkeit
- Erfasst vollständige Wörter und Phrasen, die sonst teilweise abgeschnitten würden
Richtiges Padding stellt sicher, dass Anfang und Ende nicht abgeschnitten werden – wichtig für genaue Transkription.
6. Arten von VAD-Algorithmen
6.1 Regelbasierte VAD
Regelbasierte Systeme nutzen handgefertigte akustische Merkmale und einfache Entscheidungsregeln:
- Vorteile: Leichtgewichtig und schnell, geeignet für ressourcenbeschränkte Umgebungen
- Nachteile: Weniger robust bei Rauschen und wechselnden akustischen Bedingungen
Gut in kontrollierten Umgebungen, schwächer bei realem Umgebungsgeräusch.
6.2 Statistikmodell-basierte VAD
Statistische Ansätze nutzen probabilistische Modelle:
- Gaussian Mixture Models (GMM) – modellieren die Verteilung von Sprach- und Nicht-Sprachmerkmalen
- Hidden Markov Models (HMM) – erfassen zeitliche Abhängigkeiten zwischen Frames
Robuster als rein regelbasiert, aber rechenintensiver.
6.3 Neuronales VAD (moderner Standard)
Moderne VAD nutzen Deep-Learning-Architekturen:
- CNN / RNN / Transformer
- Training auf großen, verrauschten Datensätzen
- Hohe Robustheit in vielfältigen Umgebungen
Beispiele moderner VAD:
- WebRTC VAD – weit verbreitet in Echtzeitkommunikation
- Silero VAD – leistungsstarkes neuronales VAD mit mehrsprachiger Unterstützung
Neuronales VAD ist im Produktionsbetrieb Standard wegen Genauigkeit und Robustheit.
7. VAD in ASR-Systemen
In modernen ASR-Pipelines wird VAD typischerweise vor der Erkennung eingesetzt:
Audio → VAD → Sprachsegmente → ASR-Modell → Transkription
Vorteile:
- Kürzere ASR-Inferenz durch Bearbeitung nur von Sprachsegmenten
- Stabileres Dekodieren durch Vermeidung von Rauschstörungen
- Parallele Verarbeitung langer Dateien durch Segmentierung
VAD wirkt als Filter: Nur relevante Segmente gehen in das rechenintensive ASR-Modell.
8. VAD und Zeitstempel-Abgleich
Jedes erkannte Sprachsegment behält Start- und Endzeit. Nach der Transkription werden Segment-Zeitstempel auf die globale Zeitleiste gemappt – wichtig für:
- Untertitel mit präzisem Timing
- Audio-Text-Ausrichtung z. B. für Videoschnitt
- Sprecher-Diarisierung und Segmentierung
Die Erhaltung der Zeitstempel ist entscheidend, wenn Audio und Text exakt synchron sein müssen.
9. Praktische Aspekte
Wichtige Parameter:
- Framelänge – Dauer jedes Fensters (typisch 10–30 ms)
- Schwellenwert Sprachwahrscheinlichkeit – Mindestwahrscheinlichkeit für „Sprache“
- Mindestdauer Sprache – kürzestes erlaubtes Sprachsegment
- Mindestdauer Stille – Stille, um ein Segment zu beenden
- Padding-Länge – Rand vor und nach Sprachsegmenten
Abstimmung je nach Szenario:
- Meetings: längere Stilletoleranz, mehrere Sprecher
- Podcasts: klare Sprache, wenig Hintergrund
- Callcenter: laut, wechselnde Audioqualität
Richtiges Tuning ist entscheidend für gute VAD-Leistung.
Fazit
Sprachaktivitätserkennung ist eine Grundlage der Sprachverarbeitung. Durch zuverlässige Erkennung, wann gesprochen wird, arbeiten nachgelagerte Modelle wie ASR effizienter, genauer und zuverlässiger.
In produktionsreifen Systemen ist VAD nicht optional, sondern unverzichtbar. Moderne neuronale VAD haben Robustheit und Genauigkeit stark verbessert. Mit der Weiterentwicklung der Sprachtechnik bleibt VAD ein kritischer Vorverarbeitungsschritt für optimale Pipeline-Leistung.
