Whisper verstehen: Ein umfassender Leitfaden zu OpenAIs Spracherkennungsmodell

Eric King
Author
Einleitung
OpenAIs Whisper ist ein fortschrittliches automatisches Spracherkennungsmodell (ASR), das gesprochene Audioinhalte in präzisen, lesbaren Text umwandelt. Als Open-Source-Projekt veröffentlicht, hat Whisper sich dank mehrsprachiger Fähigkeiten, Rauschrobustheit und Flexibilität in realen Szenarien schnell zu einer der am weitesten verbreiteten Transkriptionstechnologien entwickelt.
Dieser Artikel bietet einen klaren, SEO-orientierten Überblick darüber, wie Whisper funktioniert, was es auszeichnet, welche Stärken und Grenzen es hat und wie es sich gegen andere große ASR-Modelle der Branche behauptet.
Was ist Whisper?
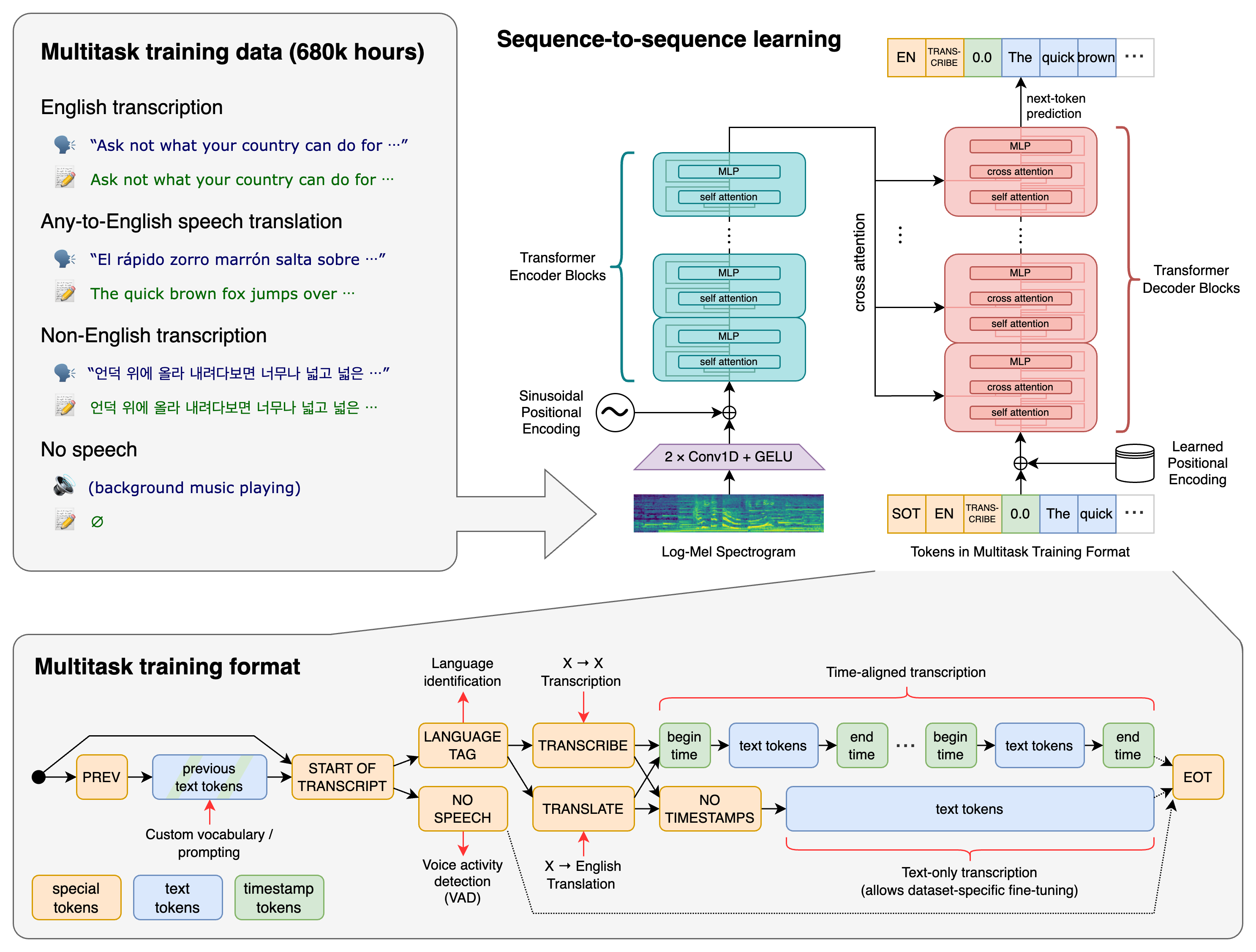
Whisper ist ein Deep-Learning-ASR-System, das auf 680.000 Stunden mehrsprachiger und multitask-fähiger überwachter Trainingsdaten aus dem Web trainiert wurde. Dazu zählen vielfältige Akzente, Rauschbedingungen und Audioqualitäten – wodurch es robuster ist als viele klassische Spracherkennungsmodelle.
Hauptaufgaben, die Whisper unterstützt:
- Sprache-zu-Text-Transkription
- Sprachübersetzung (Audio → englischer Text)
- Spracherkennung
- Zeitstempel-Erzeugung
- Mehrsprachige Transkription
Da Whisper Open Source ist, können Entwickler es lokal ausführen, Workflows feinjustieren oder in Anwendungen integrieren – ohne Drittanbieter-APIs.
Kernfunktionen von Whisper
1. Mehrsprachige Spracherkennung
Whisper unterstützt fast 100 Sprachen und eignet sich damit für globale Anwendungen und heterogene Nutzergruppen.
2. Hohe Rauschrobustheit
Dank großflächiger Trainingsdaten bewältigt Whisper:
- Hintergrundgeräusche
- Überlappende Sprache
- Nachhall
- Mikrofone geringer Qualität
Damit eignet es sich für reale Aufnahmen wie Meetings, Interviews und mobile Aufzeichnungen.
3. Wortgenaue Zeitstempel
Whisper (und Erweiterungen wie WhisperX) können präzise Zeitstempel erzeugen – für:
- Untertitel
- Podcast-Segmentierung
- Video-Untertitel-Workflows
4. Übersetzungsfähigkeiten
Whisper kann nicht-englisches Audio direkt in englischen Text übersetzen, ohne ein separates Übersetzungsmodell.
5. Vollständig Open Source
Whisper lässt sich einsetzen auf:
- On-Premise-Servern
- Cloud-VMs
- lokalen Desktops mit GPU
- Edge-Geräten
Open Source bedeutet zudem volle Kontrolle über Kosten, Datenschutz und Anpassung.
Whisper-Modellvarianten
| Modellgröße | Geschwindigkeit | Genauigkeit | Einsatzgebiet |
|---|---|---|---|
| Tiny | Am schnellsten | Am niedrigsten | Echtzeit, mobile Geräte |
| Base | Sehr schnell | Niedrig–mittel | Schnelle Transkripte |
| Small | Ausgewogen | Mittel | Allgemeine Aufgaben |
| Medium | Langsamer | Hoch | Professionelle Transkription |
| Large | Am langsamsten | Am höchsten | Maximale Genauigkeit, mehrsprachig |
Die Wahl hängt typischerweise von Rechenleistung und Genauigkeitsanforderungen ab.
Stärken von Whisper
- Hohe Genauigkeit auch unter schwierigen Bedingungen
- Bessere Handhabung von Akzenten und Dialekten als viele kommerzielle ASR-Modelle
- Mehrsprachigkeit von Haus aus
- Open Source (kein Vendor Lock-in, anpassbar)
- Zeitstempel- und Segmentierungsfähigkeiten
Grenzen von Whisper
- Für hohe Geschwindigkeit sind nennenswerte GPU-Ressourcen nötig
- Große Modelle sind auf der CPU langsam
- Bei starkem Rauschen können kleine Nicht-Sprach-Texte halluziniert werden
- Nicht für stark strukturierte Sprachaufgaben optimiert (z. B. Interpunktionsregeln in Einzelsprachen)
Für viele Nutzer mildern optimierte Forks wie Faster-Whisper, WhisperX oder GPU-Quantisierung diese Einschränkungen.
Whisper vs. andere ASR-Modelle (Wettbewerbsvergleich)
Nachfolgend ein SEO-orientierter Vergleich zwischen Whisper und anderen bekannten ASR-Systemen:
Vergleichstabelle ASR
| Merkmal / Modell | OpenAI Whisper | Google Speech-to-Text | Amazon Transcribe | Microsoft Azure STT | Deepgram |
|---|---|---|---|---|---|
| Open Source | Ja | Nein | Nein | Nein | Teilweise (nur SDK) |
| Mehrsprachigkeit | Sehr gut | Gut | Mittel | Gut | Mittel |
| Rauschrobustheit | Sehr stark | Mittel | Mittel | Mittel | Stark |
| Zeitstempel | Ja | Ja | Ja | Ja | Ja |
| Echtzeit | Begrenzt (abhängig von Hardware) | Ja | Ja | Ja | Ja |
| Kosten | Kostenlos (Self-Hosting) | Kostenpflichtig | Kostenpflichtig | Kostenpflichtig | Kostenpflichtig |
| Anpassbarkeit | Voll (Open Source) | Begrenzt | Begrenzt | Begrenzt | Mittel |
| Genauigkeit | Hoch | Hoch | Hoch | Hoch | Hoch |
Kurzfassung:
Whisper sticht durch Offenheit, Kostenvorteile und Rauschrobustheit hervor. Cloud-ASR glänzt bei Echtzeit und niedriger Latenz; Whisper bietet mehr Flexibilität und Datenschutz.
Beliebte Whisper-Erweiterungen
1. Faster-Whisper
Optimierte Implementierung mit CTranslate2. Vorteile:
- 2–4× schnellere Inferenz
- geringerer Speicherbedarf
- Unterstützung von Quantisierung (int8/int16)
Ideal für Produktionsserver.
2. WhisperX
Erweitert Whisper um:
- Wortgenaue Ausrichtung
- präzisere Zeitstempel
- Sprecher-Diarisierung (über Pyannote)
Geeignet für Untertitel, Podcasts und Medientranskription.
3. Distil-Whisper
Destillierte, kleinere, schnellere Variante mit minimalem Genauigkeitsverlust.
Wann sollten Sie Whisper einsetzen?
Whisper eignet sich, wenn Sie brauchen:
- hochgenaue Transkription
- mehrsprachige Audios
- datenschutzorientierte Bereitstellung
- anpassbare Pipelines
- kosteneffiziente ASR im großen Maßstab
- Offline- oder On-Device-Transkription
Wenn Latenz oberste Priorität hat, kann Cloud-ASR weiterhin die bessere Wahl sein.
Fazit
Whisper gehört zu den wichtigsten Fortschritten in der Open-Source-Spracherkennung. Starke Leistung, Mehrsprachigkeit und Flexibilität machen es zu einem mächtigen Werkzeug für Entwickler, Forschende und Unternehmen, die Transkriptions- oder Übersetzungsanwendungen bauen.
Mit der laufenden Community-Innovation – etwa WhisperX und Faster-Whisper – wächst das Whisper-Ökosystem weiter und bleibt eine ausgezeichnete Option für moderne ASR-Workflows.
