Detección de actividad de voz (VAD)

Eric King
Author
La detección de actividad de voz (Voice Activity Detection, VAD) es una técnica de procesamiento de señales que determina automáticamente si un segmento de audio contiene habla humana o silencio/ruido de fondo. En sistemas de voz, el VAD actúa como etapa de preprocesamiento que separa regiones de habla de regiones no verbales antes de pasos posteriores como el reconocimiento automático del habla (ASR), la traducción del habla o el análisis del hablante.
1. ¿Qué es la detección de actividad de voz?
El VAD es un componente básico de los sistemas modernos de procesamiento del habla. Realiza una clasificación binaria: para cada trama corta de audio decide si contiene habla o no habla (silencio, ruido, música, etc.).
El principio central es sencillo:
Trama de audio → modelo VAD → P(habla)
Si la probabilidad supera un umbral predefinido, la trama se clasifica como habla; en caso contrario, como no habla.
2. Por qué el VAD es importante
Las señales de audio en bruto suelen incluir:
- Largos periodos de silencio
- Ruido de fondo
- Sonidos no verbales (música, clics, respiración)
Enviar ese audio directamente a modelos ASR provoca:
- Cómputo desperdiciado al procesar silencio y ruido
- Menor precisión de reconocimiento por interferencia del ruido
- Segmentación inestable y errores de puntuación
- Mayores costes por cálculos innecesarios
Al eliminar segmentos no verbales, el VAD mejora de forma notable la eficiencia y la precisión de los modelos posteriores.
3. Canal típico de procesamiento VAD
El flujo VAD suele seguir estos pasos:
- Audio en bruto →
- Enmarcado (10–30 ms) →
- Extracción de características →
- Estimación de probabilidad de habla →
- Suavizado temporal →
- Generación de segmentos de habla
3.1 Enmarcado
La señal se divide en tramas cortas superpuestas (habitualmente 20 ms) para capturar propiedades acústicas a corto plazo. Así se analiza el audio por fragmentos manejables conservando información temporal mediante solapamiento.
3.2 Extracción de características
Características habituales en VAD:
- Energía a corto plazo – mide la potencia de la señal
- Tasa de cruces por cero – indica el contenido en frecuencia
- Entropía espectral – mide la aleatoriedad en el dominio frecuencial
- Bancos de filtros log-Mel – en VAD neuronal para mejor representación
Ayudan a distinguir habla de no habla capturando distintas propiedades acústicas.
3.3 Estimación de probabilidad de habla
Un modelo (basado en reglas o red neuronal) estima la probabilidad de que cada trama contenga habla. Se compara con un umbral para la decisión final.
3.4 Suavizado temporal
Las decisiones por trama se fusionan en segmentos continuos con reglas temporales:
- Un segmento de habla comienza cuando la probabilidad permanece por encima del umbral durante una duración mínima
- Termina cuando el silencio dura más que una duración de silencio predefinida
Así se evita el cambio frecuente entre habla y silencio por ruido o pausas breves.
4. De tramas a segmentos de habla
Las decisiones VAD por trama deben convertirse en segmentos continuos:
- Inicio de habla: el segmento empieza cuando la probabilidad se mantiene por encima del umbral durante una duración mínima
- Fin de habla: el segmento termina cuando el silencio supera una duración predefinida
Evita la fragmentación por ruido breve o pausas dentro del habla real.
5. Relleno y ajuste de bordes
Para no cortar inicios y finales, los sistemas VAD suelen aplicar padding:
- Un margen pequeño (p. ej., 100–300 ms) antes y después de los segmentos detectados
- Mejora naturalidad y precisión del reconocimiento
- Ayuda a capturar palabras y frases completas que podrían quedar parcialmente cortadas
Un padding adecuado evita truncar el principio y el final del habla, crucial para una transcripción precisa.
6. Tipos de algoritmos VAD
6.1 VAD basado en reglas
Usa características acústicas diseñadas a mano y reglas simples:
- Ventajas: ligero y rápido, adecuado para entornos con recursos limitados
- Desventajas: menos robusto al ruido y a condiciones acústicas variables
Funciona bien en entornos controlados; en ruido real cuesta más.
6.2 VAD basado en modelos estadísticos
Enfoques probabilísticos:
- Modelos de mezcla gaussiana (GMM) – modelan la distribución de características de habla y no habla
- Modelos ocultos de Markov (HMM) – capturan dependencias temporales entre tramas
Más robustos que las reglas puras, pero exigen más recursos computacionales.
6.3 VAD basado en redes neuronales (estándar moderno)
Arquitecturas de aprendizaje profundo:
- CNN / RNN / Transformer
- Entrenados con conjuntos grandes y ruidosos
- Alta robustez en entornos diversos
Ejemplos de VAD modernos:
- WebRTC VAD – muy usado en comunicación en tiempo real
- Silero VAD – VAD neuronal de alto rendimiento con soporte multilingüe
El VAD neuronal es el estándar en producción por su precisión y robustez.
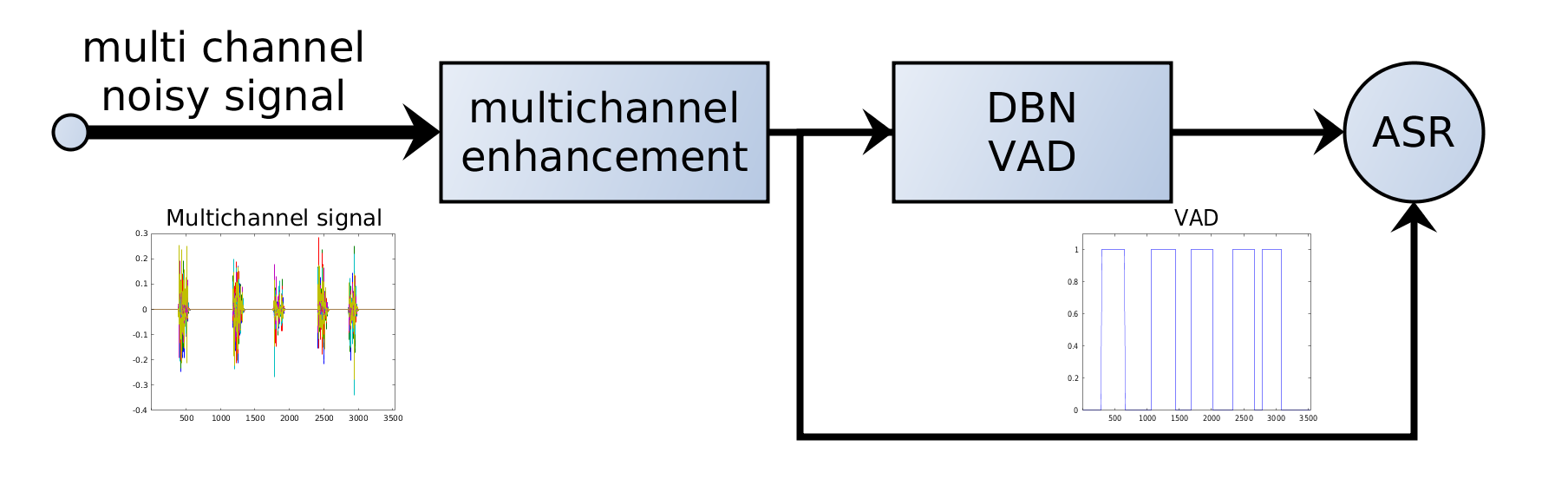
7. VAD en sistemas ASR
En canalizaciones ASR modernas, el VAD suele aplicarse antes del reconocimiento:
Audio → VAD → segmentos de habla → modelo ASR → transcripción
Beneficios:
- Reduce el tiempo de inferencia ASR al procesar solo segmentos de habla
- Mejora la estabilidad de decodificación al evitar interferencia del ruido
- Permite procesamiento en paralelo de archivos largos mediante segmentación
El VAD actúa como filtro: solo los segmentos relevantes van al modelo ASR costoso.
8. VAD y alineación de marcas de tiempo
Cada segmento conserva su tiempo de inicio y fin originales. Tras la transcripción, las marcas por segmento se proyectan a la línea de tiempo global, lo que permite:
- Subtítulos con sincronización precisa
- Alineación audio-texto para edición de vídeo, etc.
- Diarización del hablante y segmentación
Preservar marcas de tiempo es crucial cuando se requiere sincronización exacta entre audio y texto.
9. Consideraciones prácticas
Parámetros clave:
- Longitud de trama – duración de cada trama (típicamente 10–30 ms)
- Umbral de probabilidad de habla – probabilidad mínima para clasificar como habla
- Duración mínima de habla – segmento de habla más corto permitido
- Duración mínima de silencio – silencio para cerrar un segmento
- Longitud de padding – margen antes y después de los segmentos
Deben ajustarse al escenario:
- Reuniones: mayor tolerancia al silencio, varios hablantes
- Pódcasts: habla clara, poco ruido de fondo
- Call centers: entornos ruidosos, calidad variable
Un ajuste adecuado es esencial para un VAD óptimo.
Conclusión
La detección de actividad de voz es un componente fundamental del procesamiento del habla. Al detectar con precisión cuándo hay habla, permite que modelos posteriores como el ASR operen con mayor eficiencia, precisión y fiabilidad.
En sistemas de nivel de producción, el VAD no es opcional: es esencial. Los VAD neuronales modernos han avanzado mucho en robustez y precisión. A medida que evoluciona la tecnología del habla, el VAD seguirá siendo un paso de preprocesamiento crítico para el rendimiento óptimo de toda la canalización.
