Entender Whisper: guía completa del modelo de reconocimiento de voz de OpenAI

Eric King
Author
Introducción
Whisper de OpenAI es un modelo avanzado de reconocimiento automático del habla (ASR) diseñado para convertir audio hablado en texto preciso y legible. Publicado como proyecto de código abierto, Whisper se ha convertido rápidamente en una de las tecnologías de transcripción más adoptadas gracias a su soporte multilingüe, robustez ante el ruido y flexibilidad en escenarios reales.
Este artículo ofrece una visión clara y orientada al SEO de cómo funciona Whisper, qué lo hace único, sus fortalezas y limitaciones, y cómo se compara con otros modelos ASR importantes del sector.
¿Qué es Whisper?
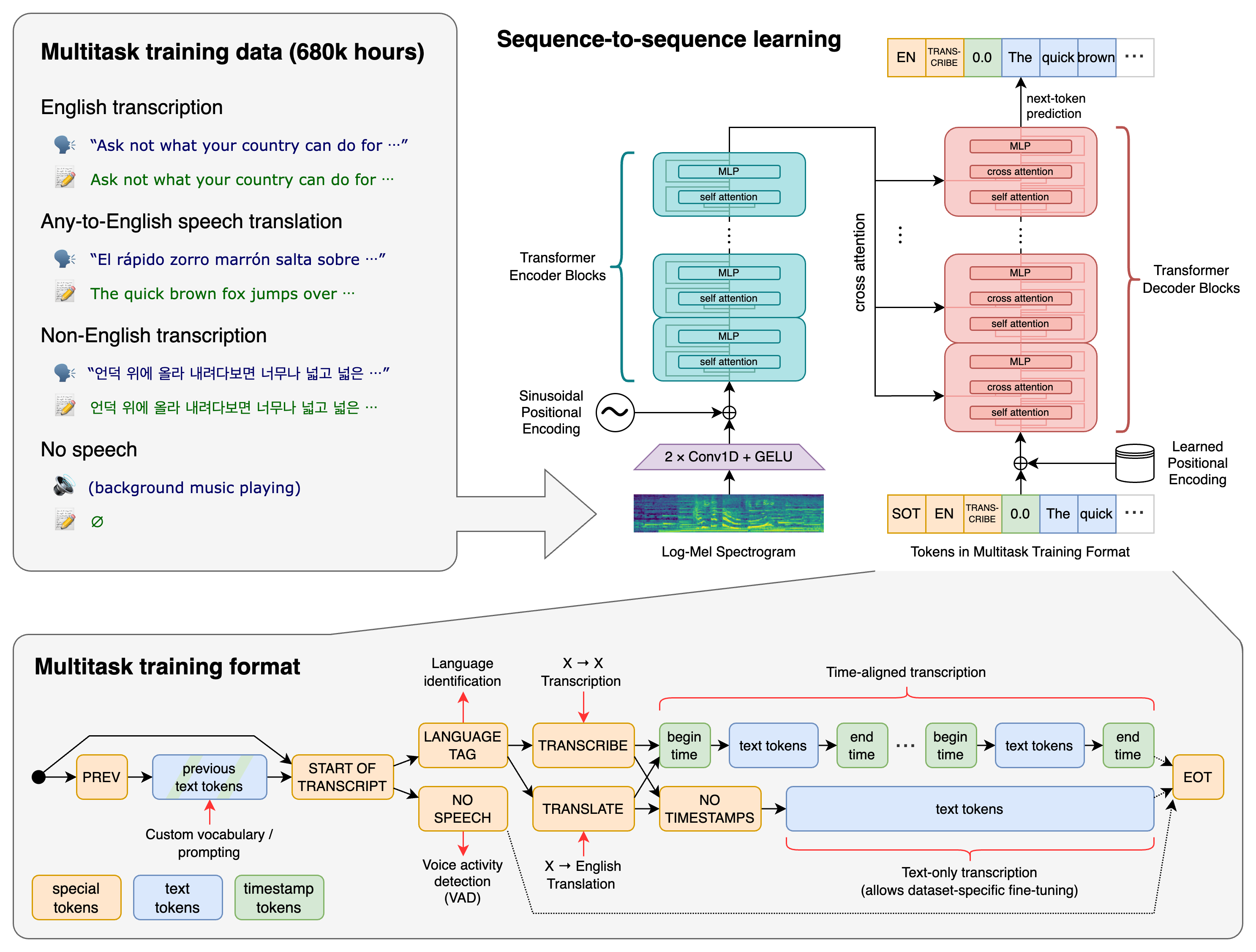
Whisper es un sistema ASR de aprendizaje profundo entrenado con 680.000 horas de datos supervisados multilingües y multitarea recopilados de la web. Su entrenamiento incluye diversos acentos, condiciones de ruido y calidades de audio, lo que lo hace mucho más robusto que muchos modelos convencionales.
Tareas principales que admite Whisper:
- Transcripción voz a texto
- Traducción de voz (audio → texto en inglés)
- Identificación de idioma
- Generación de marcas de tiempo
- Transcripción multilingüe
Al ser de código abierto, los desarrolladores pueden ejecutarlo localmente, ajustar flujos de trabajo o integrarlo en aplicaciones sin depender de APIs de terceros.
Características clave de Whisper
1. Reconocimiento multilingüe
Whisper admite casi 100 idiomas, ideal para aplicaciones globales y bases de usuarios diversas.
2. Alta robustez al ruido
Gracias a datos de entrenamiento a gran escala, Whisper maneja:
- Ruido de fondo
- Voz superpuesta
- Reverberación
- Micrófonos de baja calidad
Es adecuado para audio real: reuniones, entrevistas y grabaciones móviles.
3. Marcas de tiempo a nivel de palabra
Whisper (y extensiones como WhisperX) pueden generar marcas de tiempo precisas para:
- Subtítulos
- Segmentación de podcasts
- Flujos de subtitulado de vídeo
4. Capacidades de traducción
Whisper puede traducir audio no inglés directamente a texto en inglés sin un modelo de traducción aparte.
5. Totalmente de código abierto
Puede desplegarse en:
- Servidores on-premise
- Máquinas virtuales en la nube
- Escritorios locales con GPU
- Dispositivos edge
El código abierto implica control total sobre coste, privacidad y personalización.
Variantes del modelo Whisper
| Tamaño | Velocidad | Precisión | Caso de uso |
|---|---|---|---|
| Tiny | Más rápido | Más baja | Tiempo real, móviles |
| Base | Muy rápido | Baja–media | Transcripciones rápidas |
| Small | Equilibrado | Media | Tareas generales |
| Medium | Más lento | Alta | Transcripción profesional |
| Large | Más lento | Máxima | Máxima precisión, multilingüe |
La elección suele depender de cómputo y requisitos de precisión.
Fortalezas de Whisper
- Alta precisión incluso en condiciones difíciles
- Mejor manejo de acentos y dialectos que muchos ASR comerciales
- Soporte multilingüe integrado
- Código abierto (sin vendor lock-in, personalizable)
- Marcas de tiempo y segmentación
Limitaciones de Whisper
- Requiere GPU considerable para mayor velocidad
- Los modelos grandes pueden ser lentos en CPU
- Puede alucinar pequeños fragmentos de no voz con mucho ruido
- No optimizado para tareas de habla muy estructuradas (p. ej., reglas de puntuación por idioma)
Muchos usuarios mitigan esto con forks optimizados como Faster-Whisper, WhisperX o cuantización en GPU.
Whisper frente a otros modelos ASR
A continuación, una comparación orientada al SEO entre Whisper y otros sistemas ASR conocidos:
Tabla comparativa ASR
| Característica / modelo | OpenAI Whisper | Google Speech-to-Text | Amazon Transcribe | Microsoft Azure STT | Deepgram |
|---|---|---|---|---|---|
| Código abierto | Sí | No | No | No | Parcial (solo SDK) |
| Multilingüe | Excelente | Bueno | Medio | Bueno | Medio |
| Robustez al ruido | Muy fuerte | Moderada | Media | Media | Fuerte |
| Marcas de tiempo | Sí | Sí | Sí | Sí | Sí |
| Tiempo real | Limitado (según hardware) | Sí | Sí | Sí | Sí |
| Coste | Gratis (self-hosted) | De pago | De pago | De pago | De pago |
| Personalización | Total (open source) | Limitada | Limitada | Limitada | Media |
| Precisión | Alta | Alta | Alta | Alta | Alta |
Resumen:
Whisper destaca por su apertura, ventaja de coste y robustez al ruido. Los ASR en la nube rinden bien en baja latencia en tiempo real; Whisper ofrece más flexibilidad y privacidad.
Extensiones populares de Whisper
1. Faster-Whisper
Implementación optimizada con CTranslate2. Beneficios:
- Inferencia 2–4× más rápida
- Menor uso de memoria
- Cuantización int8/int16
Ideal para servidores de producción.
2. WhisperX
Extiende Whisper con:
- Alineación a nivel de palabra
- Marcas de tiempo más precisas
- Diarización de hablantes (vía Pyannote)
Perfecto para subtítulos, podcasts y transcripción audiovisual.
3. Distil-Whisper
Versión destilada, más pequeña y rápida, con pérdida mínima de precisión.
¿Cuándo usar Whisper?
Whisper es ideal si necesita:
- Transcripción de alta precisión
- Audio multilingüe
- Despliegues centrados en privacidad
- Pipelines personalizables
- ASR a gran escala y bajo coste
- Transcripción sin conexión o en dispositivo
Si la latencia es la prioridad absoluta, el ASR en la nube puede seguir siendo mejor opción.
Conclusión
Whisper representa uno de los avances más importantes en reconocimiento de voz de código abierto. Su rendimiento, multilingüismo y flexibilidad lo convierten en una herramienta potente para desarrolladores, investigadores y empresas que construyen aplicaciones de transcripción o traducción.
Con la innovación continua de la comunidad —WhisperX, Faster-Whisper— el ecosistema Whisper sigue creciendo y es una excelente opción para flujos ASR modernos.
