Reconnaissance vocale à faible latence : Speech-to-Text en temps réel avec SayToWords

Eric King
Author
Bienvenue sur SayToWords !
SayToWords est une plateforme alimentée par l'IA qui convertit la parole en texte avec une latence extrêmement faible.
Elle est conçue pour les utilisateurs qui ont besoin d'une transcription rapide et en temps réel sans compromettre la précision.
Elle est conçue pour les utilisateurs qui ont besoin d'une transcription rapide et en temps réel sans compromettre la précision.
Que vous transcriviez des réunions, des podcasts, des diffusions en direct ou des appels clients, la reconnaissance vocale à faible latence garantit que votre texte s'affiche presque instantanément au fur et à mesure que l'audio est prononcé.
🚀 Qu'est-ce que la reconnaissance vocale à faible latence ?
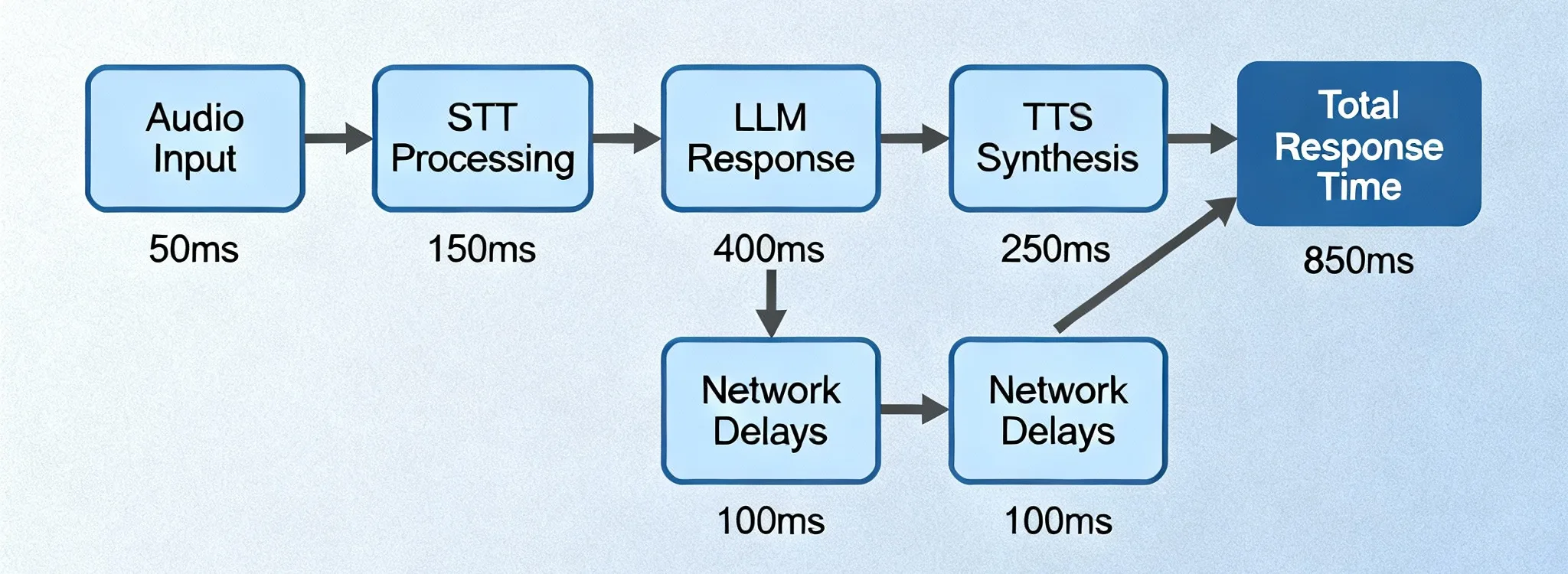
La reconnaissance vocale à faible latence consiste à convertir l'audio parlé en texte avec un délai minimal — souvent en quelques millisecondes.
En pratique, cela permet :
- Des sous-titres quasi en temps réel
- Des légendes de réunion en direct
- Un retour instantané des commandes vocales
- Une prise de notes rapide alimentée par l'IA
Plus la latence est faible, plus l'expérience utilisateur semble naturelle et réactive.
⏱ Comprendre la latence en speech-to-text
La latence est l'écart de temps entre :
Le moment où un mot est prononcé → Le moment où il apparaît sous forme de texte
- Une latence élevée entraîne des sous-titres retardés et une mauvaise utilisabilité
- Une latence faible offre une transcription fluide en temps réel
Les systèmes d'IA modernes visent à maintenir ce délai aussi faible que possible tout en conservant la précision.
⚡ Pourquoi la faible latence est importante
La reconnaissance vocale à faible latence est essentielle pour :
🎙 Réunions et conférences en direct
Les participants s'appuient sur des légendes instantanées pour l'accessibilité et la clarté.
📺 Streaming et diffusion en direct
Des sous-titres retardés réduisent l'engagement et la confiance des spectateurs.
🤖 Assistants vocaux
Une transcription rapide rend les interactions vocales naturelles.
📞 Support client et centres d'appels
Les transcriptions en temps réel aident les agents à répondre plus vite et plus intelligemment.
🧠 Comment SayToWords atteint une faible latence
SayToWords est conçu avec un pipeline de transcription IA axé sur la vitesse.
✅ Modèles IA optimisés
Nous proposons plusieurs modèles de transcription conçus pour différents besoins de latence :
- Fastest Model – latence ultra-faible, idéal pour un usage en temps réel
- Balanced Model – rapide avec une bonne précision
- Accurate Model – précision maximale pour les audios longs ou complexes
Vous pouvez choisir le modèle qui correspond le mieux à votre cas d'usage.
✅ Traitement audio par segments
L'audio est traité en petits segments, ce qui permet au texte d'apparaître progressivement au lieu d'attendre la fin du fichier complet.
Cela réduit considérablement le temps d'attente perçu.
✅ Paramètres de langue préconfigurés
En sélectionnant à l'avance la langue parlée, SayToWords évite des étapes de détection supplémentaires, ce qui réduit encore le délai de traitement.
🛠 Comment utiliser la reconnaissance vocale à faible latence sur SayToWords
📌 Étape 1 : Importez votre audio ou vidéo
Après vous être connecté, accédez au tableau de bord et cliquez sur “Transcribe Audio / Video”.
Les formats pris en charge incluent :
- MP3
- WAV
- M4A
- MP4
- MOV
📌 Étape 2 : Choisissez un modèle de transcription rapide
Pour minimiser la latence :
- Sélectionnez Fastest Model pour les enregistrements en direct ou courts
- Sélectionnez Balanced Model pour une précision en temps réel
📌 Étape 3 : Définissez la langue et les options de locuteur
- Choisissez la langue parlée
- Activez Speaker Recognition si votre audio contient plusieurs locuteurs
Ces paramètres aident à optimiser à la fois la vitesse et la précision.
📌 Étape 4 : Démarrez la transcription
Cliquez sur Transcribe et votre texte apparaîtra presque instantanément.
Vous pouvez afficher, modifier et affiner la transcription pendant que le traitement continue.
⚖️ Précision vs latence : choisir le bon modèle
Différents scénarios nécessitent différents compromis :
| Cas d'usage | Modèle recommandé |
|---|---|
| Réunions en direct | Fastest |
| Podcasts | Balanced |
| Interviews | Accurate |
| Juridique ou recherche | Accurate |
SayToWords vous donne un contrôle total sur cet équilibre.
🌍 Cas d'usage courants
La reconnaissance vocale à faible latence avec SayToWords est idéale pour :
- Légendes et sous-titres en direct
- Notes de réunion en temps réel
- Transcription de contenus en streaming
- Suivi du support client
- Workflows vocaux alimentés par l'IA
🔒 Fiable, évolutif et facile à utiliser
SayToWords est conçu pour les particuliers et les équipes :
- Gestion sécurisée des fichiers
- Infrastructure évolutive
- Prise en charge de plusieurs langues
- Basé sur le navigateur, aucune installation requise
🎯 Dernières réflexions
La reconnaissance vocale à faible latence est la base de la communication moderne en temps réel.
Avec SayToWords, vous obtenez :
- ⚡ Speech-to-text rapide à faible latence
- 🎯 Transcription IA de haute qualité
- 🌐 Prise en charge de plusieurs langues
- 🧠 Reconnaissance intelligente des locuteurs
Commencez à utiliser SayToWords dès aujourd'hui et découvrez la transcription en temps réel sans attente.
Bonne transcription ! 🎧✍️
