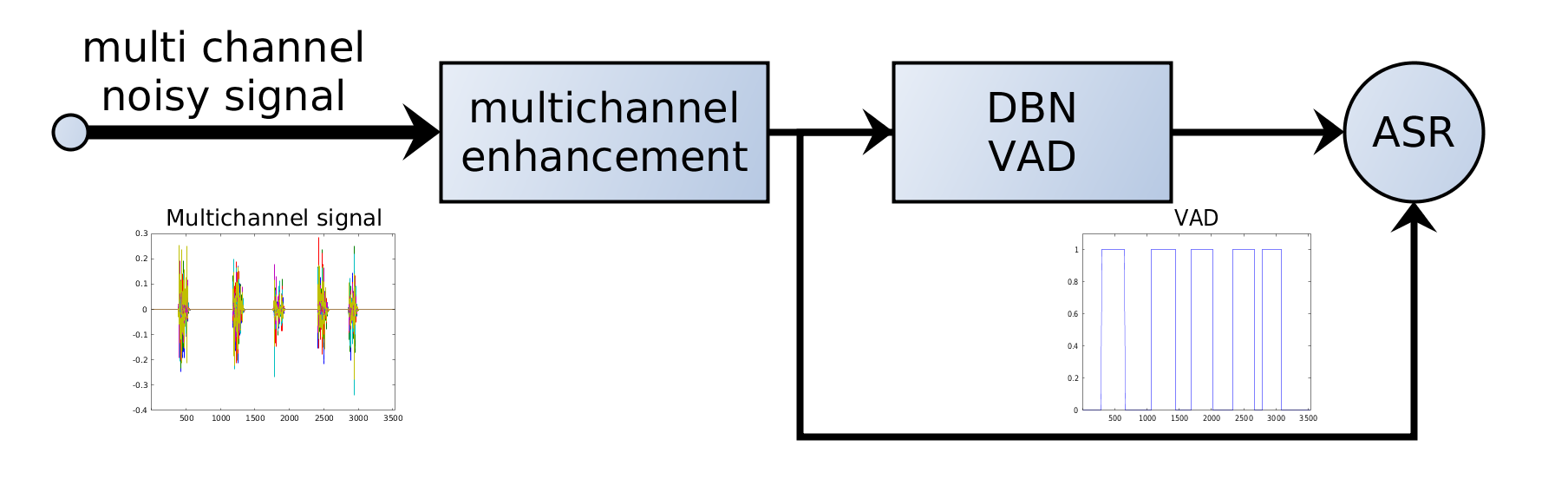
Détection d’activité vocale (VAD)

Eric King
Author
La détection d’activité vocale (Voice Activity Detection, VAD) est une technique de traitement du signal qui détermine automatiquement si un segment audio contient de la parole humaine ou du silence / du bruit de fond. Dans les systèmes vocaux, la VAD sert d’étape de prétraitement qui sépare les zones de parole des zones non verbales avant des traitements ultérieurs comme la reconnaissance automatique de la parole (ASR), la traduction vocale ou l’analyse du locuteur.
1. Qu’est-ce que la détection d’activité vocale ?
La VAD est un composant fondamental des systèmes modernes de traitement de la parole. Elle effectue une classification binaire : pour chaque courte trame audio, elle décide si la trame contient de la parole ou du non-parole (silence, bruit, musique, etc.).
Le principe de base est simple :
Trame audio → modèle VAD → P(parole)
Si la probabilité dépasse un seuil prédéfini, la trame est classée comme parole ; sinon, comme non-parole.
2. Pourquoi la VAD est importante
Les signaux audio bruts contiennent souvent :
- De longues périodes de silence
- Du bruit de fond
- Des sons non verbaux (musique, clics, respiration)
Envoyer directement de tels signaux à un modèle ASR entraîne :
- Un gaspillage de calcul sur le silence et le bruit
- Une moindre précision de reconnaissance à cause du bruit
- Une segmentation instable et des erreurs de ponctuation
- Des coûts de traitement plus élevés dus à des calculs inutiles
En supprimant les segments non verbaux, la VAD améliore nettement l’efficacité et la précision des modèles en aval.
3. Chaîne de traitement VAD typique
Le pipeline VAD suit généralement ces étapes :
- Audio brut →
- Découpage en trames (10–30 ms) →
- Extraction de caractéristiques →
- Estimation de la probabilité de parole →
- Lissage temporel →
- Génération de segments de parole
3.1 Découpage en trames
Le signal est divisé en courtes trames qui se chevauchent (souvent 20 ms) pour capturer les propriétés acoustiques à court terme. Cela permet d’analyser l’audio par morceaux tout en conservant l’information temporelle grâce au chevauchement.
3.2 Extraction de caractéristiques
Parmi les caractéristiques courantes :
- Énergie à court terme – mesure la puissance du signal
- Taux de passage par zéro – renseigne sur le contenu fréquentiel
- Entropie spectrale – mesure le caractère aléatoire dans le domaine fréquentiel
- Bancs de filtres log-Mel – utilisés dans les VAD neuronales pour une meilleure représentation
Elles aident à distinguer parole et non-parole en capturant différentes propriétés acoustiques.
3.3 Estimation de la probabilité de parole
Un modèle (à base de règles ou réseau de neurones) estime la probabilité que chaque trame contienne de la parole. Cette probabilité est comparée à un seuil pour la décision finale.
3.4 Lissage temporel
Les décisions au niveau trame sont fusionnées en segments continus par des règles temporelles :
- Un segment de parole commence lorsque la probabilité reste au-dessus du seuil pendant une durée minimale
- Un segment se termine lorsque le silence dépasse une durée de silence prédéfinie
Cela évite les basculements fréquents parole/silence dus au bruit ou à de courtes pauses.
4. Des trames aux segments de parole
Les décisions VAD par trame doivent être converties en segments continus :
- Début de parole : le segment commence lorsque la probabilité reste au-dessus du seuil pendant une durée minimale
- Fin de parole : le segment se termine lorsque le silence dépasse une durée prédéfinie
Cette approche limite la fragmentation due au bruit bref ou aux pauses dans la parole réelle.
5. Remplissage (padding) et ajustement des frontières
Pour ne pas couper les attaques et fins de parole, les systèmes VAD appliquent souvent un padding :
- Une petite marge (par ex. 100–300 ms) avant et après les segments détectés
- Cela améliore le naturel et la précision de reconnaissance
- Aide à capturer mots et phrases entiers qui risqueraient d’être tronqués
Un padding correct évite de tronquer le début et la fin des segments, ce qui est crucial pour une transcription précise.
6. Types d’algorithmes VAD
6.1 VAD à base de règles
Systèmes utilisant des caractéristiques acoustiques conçues à la main et des règles simples :
- Avantages : légers et rapides, adaptés aux environnements contraints
- Inconvénients : moins robustes au bruit et aux conditions acoustiques variables
Ils fonctionnent bien en environnement contrôlé mais peinent dans le bruit réel.
6.2 VAD basée sur des modèles statistiques
Approches probabilistes :
- Modèles de mélange gaussien (GMM) – modélisent la distribution des caractéristiques parole / non-parole
- Modèles de Markov cachés (HMM) – capturent les dépendances temporelles entre trames
Plus robustes que les règles seules, mais plus coûteuses en calcul.
6.3 VAD par réseau de neurones (standard moderne)
Architectures d’apprentissage profond :
- CNN / RNN / Transformer
- Entraînées sur de grands jeux de données bruités
- Très robustes dans des environnements variés
Exemples de VAD modernes :
- WebRTC VAD – largement utilisé en communication temps réel
- Silero VAD – VAD neuronal performant avec support multilingue
La VAD neuronale est devenue la norme en production pour sa précision et sa robustesse.
7. VAD dans les systèmes ASR
Dans les pipelines ASR modernes, la VAD est en général appliquée avant la reconnaissance :
Audio → VAD → segments de parole → modèle ASR → transcription
Avantages :
- Réduit le temps d’inférence ASR en ne traitant que la parole
- Améliore la stabilité du décodage en évitant l’interférence du bruit
- Permet le traitement parallèle de longs fichiers par segmentation
La VAD agit comme un filtre : seuls les segments pertinents sont envoyés au modèle ASR coûteux.
8. VAD et alignement des horodatages
Chaque segment détecté conserve ses temps de début et de fin d’origine. Après transcription, les horodatages par segment sont reportés sur la ligne de temps globale, ce qui assure :
- Sous-titrage avec synchronisation précise
- Alignement audio-texte pour le montage vidéo, etc.
- Diarisation des locuteurs et segmentation
La conservation des horodatages est cruciale lorsqu’il faut synchroniser précisément audio et texte.
9. Considérations pratiques
Paramètres clés :
- Longueur de trame – durée de chaque trame (souvent 10–30 ms)
- Seuil de probabilité de parole – probabilité minimale pour classer comme parole
- Durée minimale de parole – plus court segment de parole autorisé
- Durée minimale de silence – silence pour terminer un segment
- Longueur de padding – marge avant et après les segments
À régler selon le scénario :
- Réunions : tolérance au silence plus longue, plusieurs locuteurs
- Podcasts : parole claire, peu de bruit de fond
- Centres d’appel : environnements bruyants, qualité audio variable
Un réglage adapté est essentiel pour de bonnes performances VAD.
Conclusion
La détection d’activité vocale est un composant fondamental du traitement de la parole. En détectant précisément quand la parole est présente, elle permet aux modèles en aval comme l’ASR de fonctionner plus efficacement, plus précisément et plus fiablement.
Dans les systèmes de niveau production, la VAD n’est pas optionnelle : elle est indispensable. Les VAD neuronales modernes ont fortement progressé en robustesse et précision. À mesure que la technologie vocale évolue, la VAD restera une étape de prétraitement critique pour des performances optimales sur l’ensemble du pipeline.
