Comprendre Whisper : guide complet du modèle de reconnaissance vocale d’OpenAI

Eric King
Author
Introduction
Whisper d’OpenAI est un modèle avancé de reconnaissance automatique de la parole (ASR) conçu pour convertir l’audio parlé en texte précis et lisible. Publié en open source, Whisper est rapidement devenu l’une des technologies de transcription les plus adoptées grâce à ses capacités multilingues, sa robustesse au bruit et sa flexibilité dans des conditions réelles.
Cet article présente une vue d’ensemble claire et orientée SEO du fonctionnement de Whisper, de ce qui le distingue, de ses forces et limites, et de sa place par rapport aux autres grands modèles ASR du secteur.
Qu’est-ce que Whisper ?
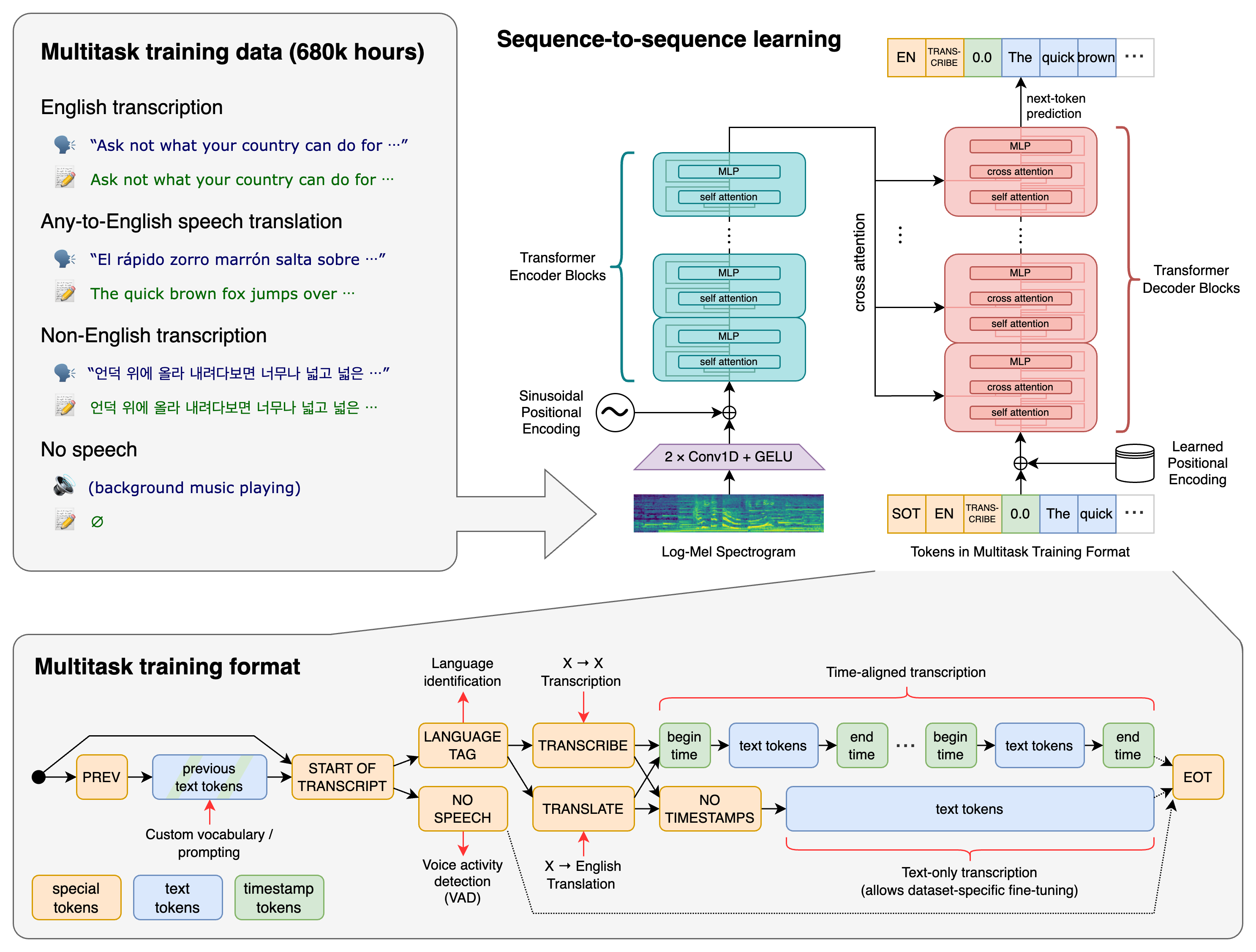
Whisper est un système ASR par apprentissage profond entraîné sur 680 000 heures de données supervisées multilingues et multitâches collectées sur le web. Son entraînement couvre des accents variés, du bruit et des qualités audio différentes — ce qui le rend bien plus robuste que de nombreux modèles classiques.
Principales tâches prises en charge :
- Transcription parole → texte
- Traduction de la parole (audio → texte anglais)
- Identification de la langue
- Génération d’horodatages
- Transcription multilingue
Étant open source, les développeurs peuvent l’exécuter localement, affiner les flux ou l’intégrer dans des applications sans dépendre d’API tierces.
Fonctionnalités clés de Whisper
1. Reconnaissance vocale multilingue
Whisper prend en charge près de 100 langues, idéal pour les applications mondiales et les publics diversifiés.
2. Forte robustesse au bruit
Grâce à un corpus d’entraînement massif, Whisper gère :
- Le bruit de fond
- La parole qui se chevauche
- La réverbération
- Les micros de faible qualité
Il convient donc à l’audio réel : réunions, interviews, enregistrements mobiles.
3. Horodatages au niveau du mot
Whisper (et des extensions comme WhisperX) peut produire des horodatages précis pour :
- Les sous-titres
- La segmentation de podcasts
- Les workflows de sous-titrage vidéo
4. Traduction
Whisper peut traduire directement de l’audio non anglais en texte anglais sans modèle de traduction séparé.
5. Entièrement open source
Whisper peut être déployé sur :
- Serveurs on-premise
- Machines virtuelles cloud
- Postes locaux avec GPU
- Appareils edge
L’open source permet un contrôle total des coûts, de la confidentialité et de la personnalisation.
Variantes du modèle Whisper
| Taille | Vitesse | Précision | Cas d’usage |
|---|---|---|---|
| Tiny | La plus rapide | La plus faible | Temps réel, mobile |
| Base | Très rapide | Faible–moyenne | Transcriptions rapides |
| Small | Équilibré | Moyenne | Tâches générales |
| Medium | Plus lent | Élevée | Transcription professionnelle |
| Large | Le plus lent | La plus élevée | Précision maximale, multilingue |
Le choix dépend généralement de la puissance de calcul et des exigences de précision.
Atouts de Whisper
- Haute précision même dans des conditions difficiles
- Meilleure gestion des accents et dialectes que de nombreux ASR commerciaux
- Support multilingue natif
- Open source (pas de verrouillage fournisseur, personnalisable)
- Horodatages et segmentation
Limites de Whisper
- Nécessite des ressources GPU importantes pour de hautes vitesses
- Les grands modèles peuvent être lents sur CPU
- Risque de petites hallucinations de texte non parlé dans un audio très bruité
- Pas optimisé pour des tâches de parole très structurées (ex. règles de ponctuation par langue)
Des forks optimisés comme Faster-Whisper, WhisperX ou la quantification GPU atténuent souvent ces limites.
Whisper vs autres modèles ASR
Comparaison orientée SEO entre Whisper et d’autres systèmes ASR connus :
Tableau comparatif ASR
| Fonctionnalité / modèle | OpenAI Whisper | Google Speech-to-Text | Amazon Transcribe | Microsoft Azure STT | Deepgram |
|---|---|---|---|---|---|
| Open source | Oui | Non | Non | Non | Partiel (SDK seulement) |
| Multilingue | Excellent | Bon | Moyen | Bon | Moyen |
| Robustesse au bruit | Très forte | Modérée | Moyenne | Moyenne | Forte |
| Horodatages | Oui | Oui | Oui | Oui | Oui |
| Temps réel | Limité (selon matériel) | Oui | Oui | Oui | Oui |
| Coût | Gratuit (self-hébergé) | Payant | Payant | Payant | Payant |
| Personnalisation | Totale (open source) | Limitée | Limitée | Limitée | Moyenne |
| Précision | Élevée | Élevée | Élevée | Élevée | Élevée |
Synthèse :
Whisper se distingue par son ouverture, son avantage coût et sa robustesse au bruit. Les ASR cloud excellent en temps réel à faible latence ; Whisper offre plus de flexibilité et de confidentialité.
Extensions populaires de Whisper
1. Faster-Whisper
Implémentation optimisée avec CTranslate2. Avantages :
- Inférence 2 à 4× plus rapide
- Mémoire réduite
- Quantification int8/int16
Idéal pour les serveurs de production.
2. WhisperX
Étend Whisper avec :
- Alignement au niveau du mot
- Horodatages plus précis
- Diarisation des locuteurs (via Pyannote)
Parfait pour sous-titres, podcasts et transcription média.
3. Distil-Whisper
Version distillée, plus petite et plus rapide, avec une perte de précision minimale.
Quand utiliser Whisper ?
Whisper convient si vous avez besoin de :
- transcription haute précision
- audio multilingue
- déploiements axés confidentialité
- pipelines personnalisables
- ASR à grande échelle et coût maîtrisé
- transcription hors ligne ou sur appareil
Si la latence est la priorité absolue, l’ASR cloud peut rester préférable.
Conclusion
Whisper compte parmi les avancées majeures de la reconnaissance vocale open source. Ses performances, son multilinguisme et sa flexibilité en font un outil puissant pour développeurs, chercheurs et entreprises qui créent des applications de transcription ou de traduction.
Avec l’innovation continue de la communauté — WhisperX, Faster-Whisper — l’écosystème Whisper grandit et reste un excellent choix pour les workflows ASR modernes.
