Riconoscimento vocale a bassa latenza: speech-to-text in tempo reale con SayToWords

Eric King
Author
Benvenuto in SayToWords!
SayToWords è una piattaforma basata sull'AI che converte la voce in testo con latenza estremamente bassa.
È progettata per utenti che hanno bisogno di trascrizioni veloci e in tempo reale senza sacrificare l'accuratezza.
È progettata per utenti che hanno bisogno di trascrizioni veloci e in tempo reale senza sacrificare l'accuratezza.
Che tu stia trascrivendo riunioni, podcast, live stream o chiamate con clienti, il riconoscimento vocale a bassa latenza garantisce che il testo appaia quasi istantaneamente mentre l'audio viene pronunciato.
🚀 Che cos'è il riconoscimento vocale a bassa latenza?
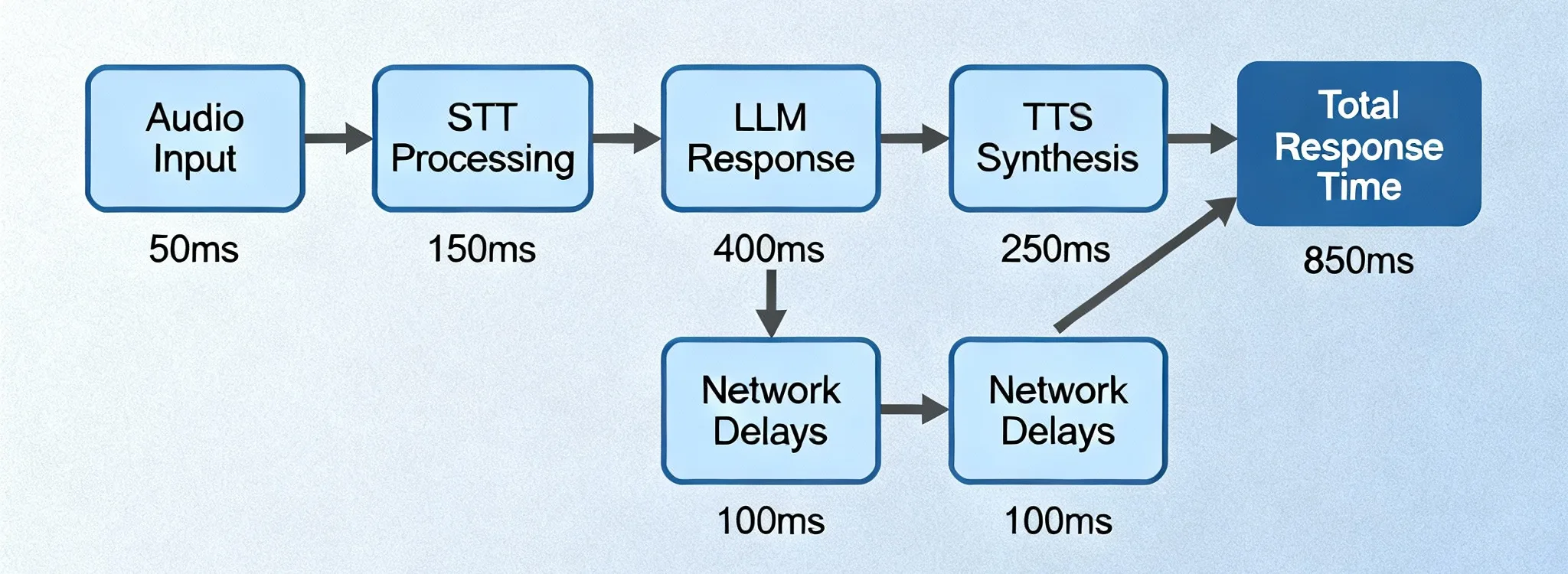
Il riconoscimento vocale a bassa latenza significa convertire l'audio parlato in testo con ritardo minimo, spesso entro pochi millisecondi.
In termini pratici, consente:
- Sottotitoli quasi in tempo reale
- Didascalie live per riunioni
- Feedback istantaneo ai comandi vocali
- Presa di appunti rapida con AI
Più bassa è la latenza, più l'esperienza utente risulta naturale e reattiva.
⏱ Capire la latenza nello speech-to-text
La latenza è il divario di tempo tra:
Quando una parola viene pronunciata → Quando appare come testo
- Latenza alta causa sottotitoli in ritardo e scarsa usabilità
- Latenza bassa offre trascrizione fluida in tempo reale
I moderni sistemi AI puntano a mantenere questo ritardo il più ridotto possibile, preservando l'accuratezza.
⚡ Perché la bassa latenza è importante
Il riconoscimento vocale a bassa latenza è essenziale per:
🎙 Riunioni e conferenze live
I partecipanti si affidano a didascalie istantanee per accessibilità e chiarezza.
📺 Live streaming e broadcasting
Sottotitoli in ritardo riducono coinvolgimento e fiducia degli spettatori.
🤖 Assistenti vocali
Una trascrizione rapida rende le interazioni vocali naturali.
📞 Supporto clienti e call center
Le trascrizioni in tempo reale aiutano gli operatori a rispondere più velocemente e in modo più intelligente.
🧠 Come SayToWords ottiene bassa latenza
SayToWords è costruito con una pipeline di trascrizione AI orientata alla velocità.
✅ Modelli AI ottimizzati
Offriamo più modelli di trascrizione progettati per diverse esigenze di latenza:
- Fastest Model – latenza ultra-bassa, ideale per uso in tempo reale
- Balanced Model – veloce con forte accuratezza
- Accurate Model – massima accuratezza per audio lunghi o complessi
Puoi scegliere il modello più adatto al tuo caso d'uso.
✅ Elaborazione audio basata su chunk
L'audio viene elaborato in piccoli segmenti, permettendo al testo di apparire progressivamente invece di aspettare il completamento dell'intero file.
Questo riduce significativamente il tempo di attesa percepito.
✅ Impostazioni lingua preconfigurate
Selezionando in anticipo la lingua parlata, SayToWords evita passaggi extra di rilevamento, riducendo ulteriormente il ritardo di elaborazione.
🛠 Come usare il riconoscimento vocale a bassa latenza su SayToWords
📌 Passaggio 1: carica il tuo audio o video
Dopo aver effettuato l'accesso, vai alla dashboard e clicca “Transcribe Audio / Video”.
I formati supportati includono:
- MP3
- WAV
- M4A
- MP4
- MOV
📌 Passaggio 2: scegli un modello di trascrizione veloce
Per ridurre al minimo la latenza:
- Seleziona Fastest Model per registrazioni live o brevi
- Seleziona Balanced Model per accuratezza in tempo reale
📌 Passaggio 3: imposta lingua e opzioni speaker
- Scegli la lingua parlata
- Abilita Speaker Recognition se il tuo audio ha più speaker
Queste impostazioni aiutano a ottimizzare sia velocità sia accuratezza.
📌 Passaggio 4: avvia la trascrizione
Clicca Transcribe e il tuo testo apparirà quasi istantaneamente.
Puoi visualizzare, modificare e perfezionare la trascrizione mentre l'elaborazione continua.
⚖️ Accuratezza vs latenza: scegliere il modello giusto
Scenari diversi richiedono compromessi diversi:
| Use Case | Recommended Model |
|---|---|
| Live meetings | Fastest |
| Podcasts | Balanced |
| Interviews | Accurate |
| Legal or research | Accurate |
SayToWords ti offre controllo completo su questo equilibrio.
🌍 Casi d'uso comuni
Il riconoscimento vocale a bassa latenza con SayToWords è ideale per:
- Didascalie e sottotitoli live
- Note riunione in tempo reale
- Trascrizione di contenuti in streaming
- Monitoraggio del supporto clienti
- Flussi vocali basati su AI
🔒 Affidabile, scalabile e facile da usare
SayToWords è pensato per individui e team:
- Gestione sicura dei file
- Infrastruttura scalabile
- Supporto multilingua
- Basato su browser, nessuna installazione richiesta
🎯 Considerazioni finali
Il riconoscimento vocale a bassa latenza è la base della moderna comunicazione in tempo reale.
Con SayToWords, ottieni:
- ⚡ Speech-to-text rapido e a bassa latenza
- 🎯 Trascrizione AI di alta qualità
- 🌐 Supporto multilingua
- 🧠 Riconoscimento speaker intelligente
Inizia a usare SayToWords oggi stesso e prova una trascrizione in tempo reale senza attese.
Buona trascrizione! 🎧✍️
