Rilevamento dell’attività vocale (VAD)

Eric King
Author
Il rilevamento dell’attività vocale (Voice Activity Detection, VAD) è una tecnica di elaborazione dei segnali usata per determinare automaticamente se un segmento audio contiene parlato umano o silenzio/rumore di fondo. Nei sistemi vocali, il VAD funge da fase di pre-elaborazione che separa le regioni di parlato da quelle non vocali prima di ulteriori passaggi come il riconoscimento automatico del parlato (ASR), la traduzione vocale o l’analisi del parlante.
1. Cos’è il rilevamento dell’attività vocale?
Il VAD è un componente fondamentale dei moderni sistemi di elaborazione del parlato. Esegue una classificazione binaria: per ogni breve frame audio stabilisce se contiene parlato o non-parlato (silenzio, rumore, musica, ecc.).
Il principio di base è semplice:
Frame audio → modello VAD → P(parlato)
Se la probabilità supera una soglia predefinita, il frame è classificato come parlato; altrimenti come non-parlato.
2. Perché il VAD è importante
I segnali audio grezzi spesso contengono:
- Lunghi periodi di silenzio
- Rumore di fondo
- Suoni non vocali (musica, clic, respiro)
Inviare tale audio direttamente ai modelli ASR comporta:
- Calcolo sprecato su silenzio e rumore
- Minore accuratezza di riconoscimento per interferenza del rumore
- Segmentazione instabile ed errori di punteggiatura
- Costi di elaborazione più elevati per calcoli non necessari
Rimuovendo i segmenti non vocali, il VAD migliora sensibilmente efficienza e accuratezza dei modelli a valle.
3. Pipeline tipica di elaborazione VAD
La pipeline VAD segue questi passaggi:
- Audio grezzo →
- Suddivisione in frame (10–30 ms) →
- Estrazione di caratteristiche →
- Stima della probabilità di parlato →
- Smoothing temporale →
- Generazione di segmenti di parlato
3.1 Suddivisione in frame
Il segnale è diviso in brevi frame sovrapposti (comunemente 20 ms) per catturare proprietà acustiche a breve termine. Consente di analizzare l’audio a blocchi gestibili preservando l’informazione temporale tramite sovrapposizione.
3.2 Estrazione di caratteristiche
Caratteristiche comuni nel VAD:
- Energia a breve termine – misura la potenza del segnale
- Tasso di attraversamento dello zero – indica il contenuto in frequenza
- Entropia spettrale – misura la casualità nel dominio delle frequenze
- Banchi di filtri log-Mel – nei VAD neurali per una rappresentazione migliore
Aiutano a distinguere parlato e non-parlato catturando proprietà acustiche diverse.
3.3 Stima della probabilità di parlato
Un modello (basato su regole o rete neurale) stima la probabilità che ogni frame contenga parlato. La probabilità è confrontata con una soglia per la decisione finale.
3.4 Smoothing temporale
Le decisioni a livello di frame sono unite in segmenti continui con regole temporali:
- Un segmento di parlato inizia quando la probabilità resta sopra la soglia per una durata minima
- Un segmento termina quando il silenzio persiste oltre una durata predefinita
Evita commutazioni frequenti tra parlato e silenzio per rumore o brevi pause.
4. Dai frame ai segmenti di parlato
Le decisioni VAD per frame vanno convertite in segmenti continui:
- Inizio parlato: il segmento inizia quando la probabilità resta sopra la soglia per una durata minima
- Fine parlato: il segmento termina quando il silenzio supera una durata predefinita
Previene la frammentazione dovuta a rumore breve o pause nel parlato reale.
5. Padding e aggiustamento dei bordi
Per non tagliare attacchi e conclusioni del parlato, i sistemi VAD applicano di solito padding:
- Un piccolo margine (es. 100–300 ms) prima e dopo i segmenti rilevati
- Migliora naturalezza e accuratezza del riconoscimento
- Aiuta a catturare parole e frasi complete che altrimenti sarebbero troncate
Un padding adeguato evita il troncamento di inizio e fine, cruciale per una trascrizione accurata.
6. Tipi di algoritmi VAD
6.1 VAD basato su regole
Usa caratteristiche acustiche progettate a mano e regole semplici:
- Vantaggi: leggero e veloce, adatto ad ambienti con risorse limitate
- Svantaggi: meno robusto al rumore e a condizioni acustiche variabili
Funziona bene in ambienti controllati; fatica nel rumore reale.
6.2 VAD basato su modelli statistici
Approcci probabilistici:
- Modelli a mistura gaussiana (GMM) – modellano la distribuzione delle caratteristiche di parlato e non-parlato
- Modelli di Markov nascosti (HMM) – catturano dipendenze temporali tra frame
Più robusti delle sole regole, ma richiedono più risorse computazionali.
6.3 VAD basato su reti neurali (standard moderno)
Architetture di deep learning:
- CNN / RNN / Transformer
- Addestrate su dataset grandi e rumorosi
- Alta robustezza in ambienti diversi
Esempi di VAD moderni:
- WebRTC VAD – molto usato nella comunicazione in tempo reale
- Silero VAD – VAD neurale ad alte prestazioni con supporto multilingue
Il VAD neurale è lo standard in produzione per accuratezza e robustezza superiori.
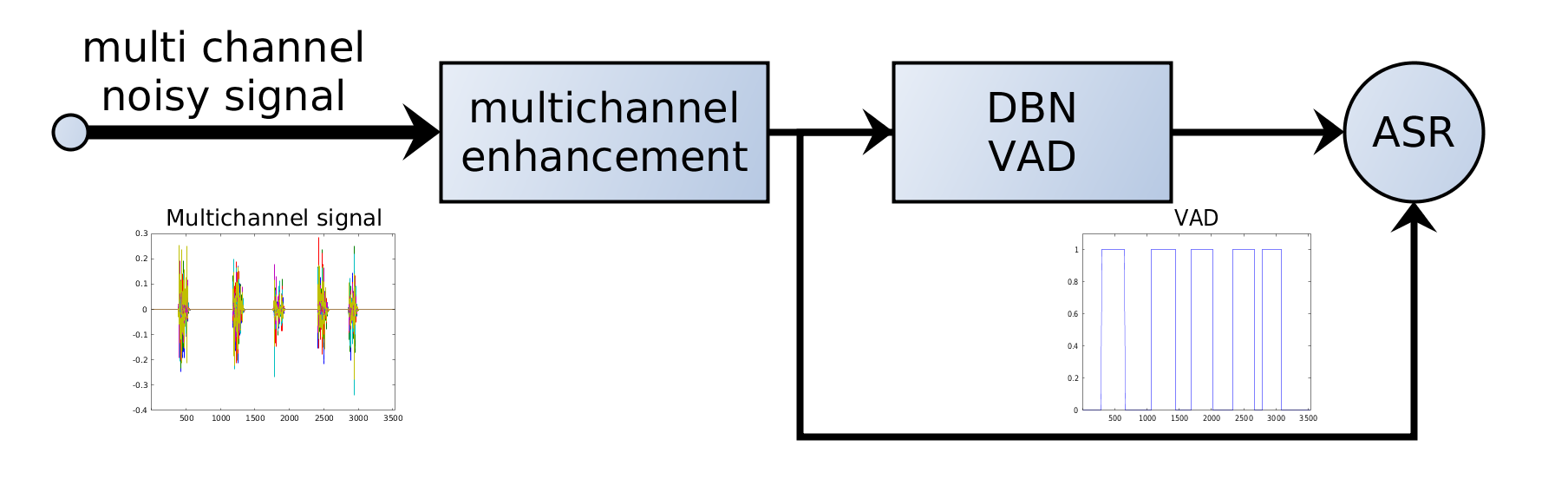
7. VAD nei sistemi ASR
Nelle pipeline ASR moderne il VAD si applica in genere prima del riconoscimento:
Audio → VAD → segmenti di parlato → modello ASR → trascrizione
Vantaggi:
- Riduce il tempo di inferenza ASR elaborando solo i segmenti di parlato
- Migliora la stabilità della decodifica evitando interferenza del rumore
- Abilita elaborazione parallela di file lunghi tramite segmentazione
Il VAD funge da filtro: solo i segmenti rilevanti vanno al modello ASR costoso.
8. VAD e allineamento dei timestamp
Ogni segmento mantiene i tempi di inizio e fine originali. Dopo la trascrizione, i timestamp a livello di segmento sono mappati sulla timeline globale, garantendo:
- Sottotitolazione con tempistica precisa
- Allineamento audio-testo per montaggio video, ecc.
- Diarizzazione del parlante e segmentazione
La conservazione dei timestamp è cruciale quando serve sincronizzazione precisa tra audio e testo.
9. Considerazioni pratiche
Parametri chiave:
- Lunghezza del frame – durata di ogni frame (tipicamente 10–30 ms)
- Soglia di probabilità di parlato – probabilità minima per classificare come parlato
- Durata minima di parlato – segmento di parlato più corto consentito
- Durata minima di silenzio – silenzio per chiudere un segmento
- Lunghezza del padding – margine prima e dopo i segmenti
Vanno tarati in base allo scenario:
- Riunioni: maggiore tolleranza al silenzio, più parlanti
- Podcast: parlato chiaro, poco rumore di fondo
- Call center: ambienti rumorosi, qualità audio variabile
Una taratura corretta è essenziale per prestazioni VAD ottimali.
Conclusione
Il rilevamento dell’attività vocale è un componente fondamentale dell’elaborazione del parlato. Rilevando con precisione quando c’è parlato, consente a modelli a valle come l’ASR di operare in modo più efficiente, accurato e affidabile.
Nei sistemi di livello produzione il VAD non è opzionale: è essenziale. I VAD neurali moderni hanno compiuto grandi passi in robustezza e accuratezza. Con l’evoluzione della tecnologia vocale, il VAD resterà un passo di pre-elaborazione critico per le prestazioni ottimali dell’intera pipeline.
