Capire Whisper: guida completa al modello di riconoscimento vocale di OpenAI

Eric King
Author
Introduzione
Whisper di OpenAI è un modello avanzato di riconoscimento automatico del parlato (ASR) progettato per convertire l’audio parlato in testo accurato e leggibile. Rilasciato come progetto open source, Whisper è rapidamente diventato una delle tecnologie di trascrizione più diffuse grazie alle capacità multilingue, alla robustezza al rumore e alla flessibilità in scenari reali.
Questo articolo offre una panoramica chiara e orientata al SEO su come funziona Whisper, cosa lo rende unico, punti di forza e limiti, e come si confronta con altri importanti modelli ASR del settore.
Cos’è Whisper?
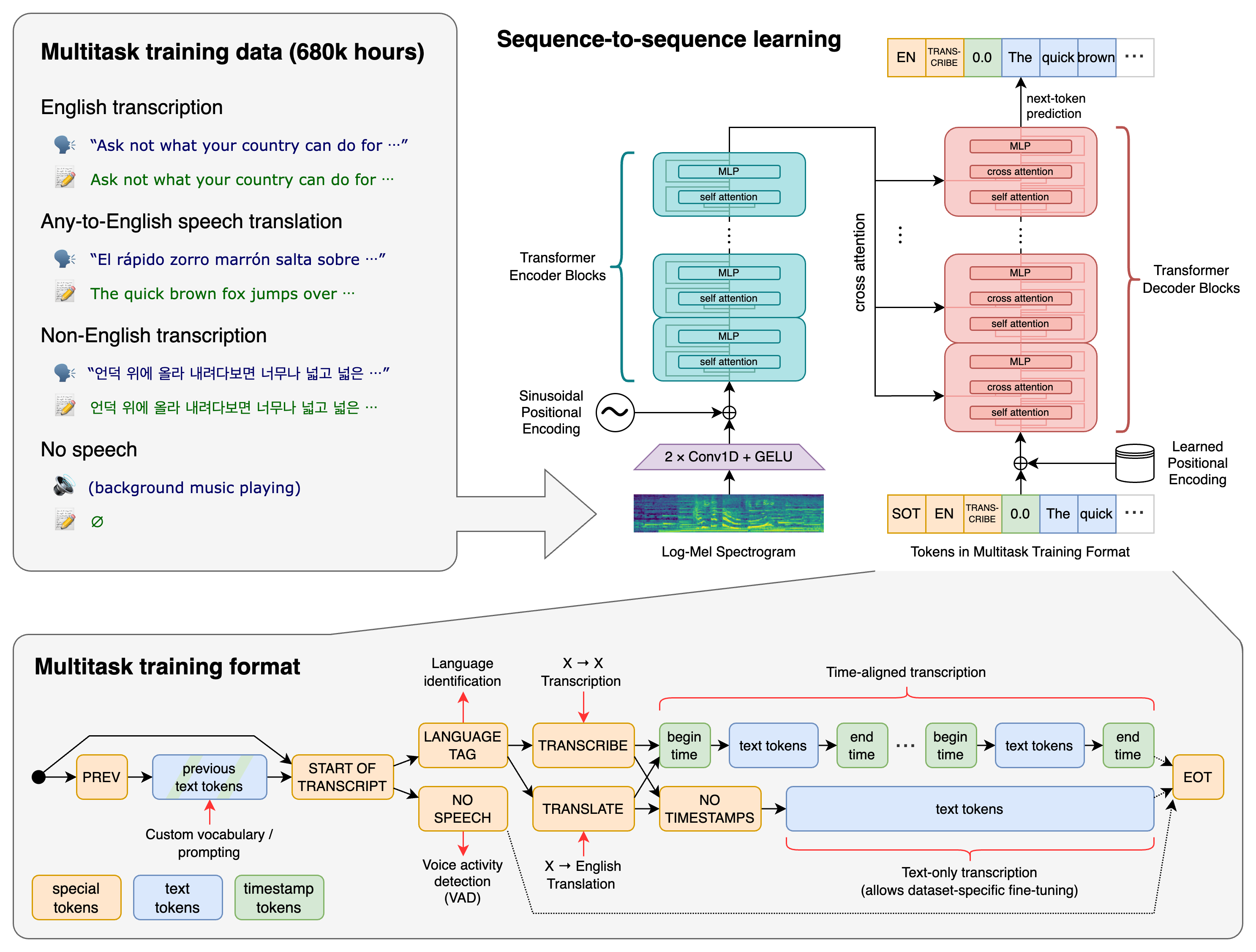
Whisper è un sistema ASR di deep learning addestrato su 680.000 ore di dati supervisionati multilingue e multitask raccolti dal web. L’addestramento include accenti diversi, condizioni di rumore e qualità audio variabili, rendendolo molto più robusto di molti modelli convenzionali.
Compiti principali supportati da Whisper:
- Trascrizione voce-testo
- Traduzione del parlato (audio → testo inglese)
- Identificazione della lingua
- Generazione di timestamp
- Trascrizione multilingue
Essendo open source, gli sviluppatori possono eseguirlo in locale, ottimizzare i flussi di lavoro o integrarlo nelle applicazioni senza dipendere da API di terze parti.
Caratteristiche principali di Whisper
1. Riconoscimento vocale multilingue
Whisper supporta quasi 100 lingue, ideale per applicazioni globali e utenti diversificati.
2. Elevata robustezza al rumore
Grazie a dati di training su larga scala, Whisper gestisce:
- Rumore di fondo
- Parlato sovrapposto
- Riverbero
- Microfoni di bassa qualità
Adatto ad audio reale: riunioni, interviste, registrazioni mobili.
3. Timestamp a livello di parola
Whisper (e estensioni come WhisperX) possono generare timestamp accurati per:
- Sottotitoli
- Segmentazione podcast
- Flussi di sottotitolazione video
4. Capacità di traduzione
Whisper può tradurre direttamente audio non inglese in testo inglese senza un modello di traduzione separato.
5. Completamente open source
È possibile distribuire Whisper su:
- Server on-premise
- VM cloud
- Desktop locali con GPU
- Dispositivi edge
L’open source significa controllo completo su costi, privacy e personalizzazione.
Varianti del modello Whisper
| Dimensione | Velocità | Precisione | Caso d’uso |
|---|---|---|---|
| Tiny | Più veloce | Più bassa | Tempo reale, dispositivi mobili |
| Base | Molto veloce | Bassa-media | Trascrizioni rapide |
| Small | Bilanciato | Media | Compiti generali |
| Medium | Più lenta | Alta | Trascrizione professionale |
| Large | Più lenta | Massima | Massima precisione, multilingue |
La scelta dipende in genere da risorse di calcolo e requisiti di accuratezza.
Punti di forza di Whisper
- Alta accuratezza anche in condizioni difficili
- Migliore gestione di accenti e dialetti rispetto a molti ASR commerciali
- Supporto multilingue integrato
- Open source (niente vendor lock-in, personalizzabile)
- Timestamp e segmentazione
Limitazioni di Whisper
- Richiede GPU significative per alte velocità
- I modelli grandi possono essere lenti su CPU
- Può allucinare piccoli frammenti di non-parlato in audio molto rumoroso
- Non ottimizzato per compiti di parlato altamente strutturati (es. regole di punteggiatura per lingua)
Fork ottimizzati come Faster-Whisper, WhisperX o quantizzazione GPU mitigano spesso questi limiti.
Whisper vs altri modelli ASR
Confronto orientato al SEO tra Whisper e altri sistemi ASR noti:
Tabella comparativa ASR
| Funzione / modello | OpenAI Whisper | Google Speech-to-Text | Amazon Transcribe | Microsoft Azure STT | Deepgram |
|---|---|---|---|---|---|
| Open source | Sì | No | No | No | Parziale (solo SDK) |
| Multilingue | Eccellente | Buono | Medio | Buono | Medio |
| Robustez al rumore | Molto forte | Moderata | Media | Media | Forte |
| Timestamp | Sì | Sì | Sì | Sì | Sì |
| Tempo reale | Limitato (dipende dall’hardware) | Sì | Sì | Sì | Sì |
| Costo | Gratuito (self-hosted) | A pagamento | A pagamento | A pagamento | A pagamento |
| Personalizzazione | Totale (open source) | Limitata | Limitata | Limitata | Media |
| Accuratezza | Alta | Alta | Alta | Alta | Alta |
Sintesi:
Whisper si distingue per apertura, vantaggio sui costi e robustezza al rumore. Gli ASR cloud eccellono in scenari real-time a bassa latenza; Whisper offre maggiore flessibilità e privacy.
Estensioni popolari di Whisper
1. Faster-Whisper
Implementazione ottimizzata con CTranslate2. Vantaggi:
- Inferenza 2–4× più veloce
- Minore uso di memoria
- Supporto alla quantizzazione (int8/int16)
Ideale per server di produzione.
2. WhisperX
Estende Whisper con:
- Allineamento a livello di parola
- Timestamp più accurati
- Diarizzazione degli speaker (via Pyannote)
Perfetto per sottotitoli, podcast e trascrizione media.
3. Distil-Whisper
Versione distillata, più piccola e veloce, con perdita minima di accuratezza.
Quando usare Whisper?
Whisper è ideale se servono:
- trascrizione ad alta accuratezza
- audio multilingue
- distribuzioni orientate alla privacy
- pipeline personalizzabili
- ASR su larga scala ed economico
- trascrizione offline o on-device
Se la latenza è la priorità assoluta, l’ASR cloud può essere ancora preferibile.
Conclusione
Whisper rappresenta uno dei progressi più importanti nel riconoscimento vocale open source. Prestazioni solide, multilinguismo e flessibilità lo rendono uno strumento potente per sviluppatori, ricercatori e aziende che costruiscono applicazioni di trascrizione o traduzione.
Con l’innovazione continua della community — WhisperX, Faster-Whisper — l’ecosistema Whisper continua a crescere ed è un’ottima scelta per i flussi ASR moderni.
