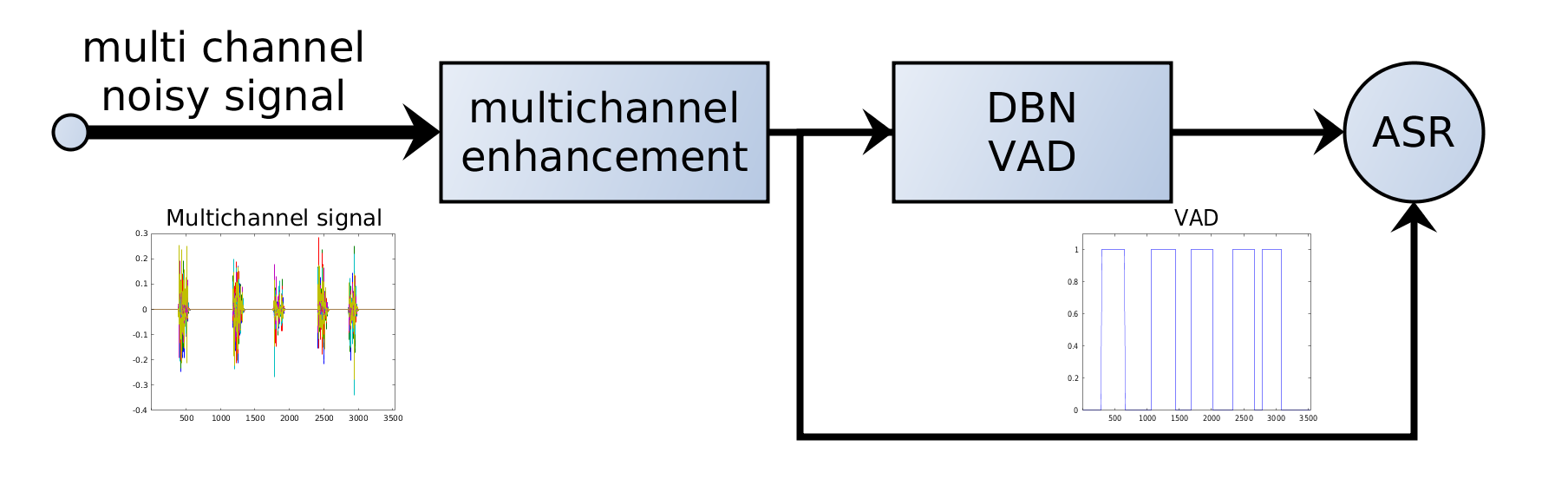
音声活動検出(VAD)

Eric King
Author
音声活動検出(Voice Activity Detection、VAD)は、与えられた音声区間に人間の発話が含まれるか、無音/背景雑音かを自動的に判定する信号処理手法です。音声システムでは、自動音声認識(ASR)、音声翻訳、話者分析などの前処理として、発話領域と非発話領域を分離する段階として機能します。
1. 音声活動検出とは
VADは現代の音声処理システムの基本要素です。短い音声フレームごとに、そのフレームが発話か非発話(無音、雑音、音楽など)かを二値分類します。
核心は次のとおりです。
音声フレーム → VADモデル → P(発話)
確率が事前に定めた閾値を超えれば発話、そうでなければ非発話と判定します。
2. VADが重要な理由
生の音声には次のようなものが多く含まれます。
- 長い無音
- 背景雑音
- 非発話音(音楽、クリック、呼吸音など)
これをそのままASRモデルに入れると次の問題が生じます。
- 無音や雑音の処理による計算の浪費
- 雑音干渉による認識精度の低下
- 不安定なセグメンテーションと句読点の誤り
- 不要な計算による処理コストの増加
非発話区間を除くことで、VADは下流の音声モデルの効率と精度を大きく改善します。
3. 典型的なVAD処理パイプライン
VADの流れは概ね次のとおりです。
- 生音声 →
- フレーム分割(10〜30 ms) →
- 特徴抽出 →
- 発話確率の推定 →
- 時間的スムージング →
- 発話区間の生成
3.1 フレーム分割
信号を短い重なり付きフレーム(多くは20 ms)に分け、短時間の音響特性を捉えます。オーバーラップにより時間情報を保ちつつ、扱いやすい単位で解析します。
3.2 特徴抽出
VADでよく使う特徴には次があります。
- 短時間エネルギー — 信号のパワー
- ゼロクロス率 — 周波数内容の指標
- スペクトルエントロピー — 周波数領域のランダム性
- 対数メルフィルタバンク — ニューラルVADで表現力向上
異なる音響特性により発話と非発話を区別します。
3.3 発話確率の推定
ルールベースまたはニューラルネットワークのモデルが、各フレームに発話が含まれる尤度を推定し、閾値と比較して最終判定します。
3.4 時間的スムージング
フレーム単位の判定を時間ルールで連続した発話区間にまとめます。
- 発話確率が閾値を一定時間以上上回り続けたら区間開始
- 無音が所定時間を超えたら区間終了
雑音や短い休止による発話/無音の頻繁な切り替えを抑えます。
4. フレームから発話区間へ
フレーム単位のVAD結果を連続区間に変換するルールは次のとおりです。
- 発話開始:確率が閾値を最小継続時間上回ると区間開始
- 発話終了:無音が所定の無音継続時間を超えると区間終了
短い雑音や発話内の休止による細切れを防ぎます。
5. パディングと境界調整
発話の立ち上がり・切れ目を落とさないため、多くのVADはパディングを行います。
- 検出区間の前後に小さなマージン(例:100〜300 ms)を追加
- 自然さと認識精度の向上
- 端で欠ける語句の捕捉
適切なパディングは、転写精度にとって重要です。
6. VADアルゴリズムの種類
6.1 ルールベースVAD
手設計の音響特徴と単純な判定規則を用います。
- 利点:軽量・高速、リソース制約下に適する
- 欠点:雑音や条件変化に弱い
制御された環境では有効ですが、実環境の雑音では苦戦しがちです。
6.2 統計モデルベースVAD
確率モデルを用います。
- 混合ガウスモデル(GMM) — 発話/非発話特徴の分布をモデル化
- 隠れマルコフモデル(HMM) — フレーム間の時間依存を表現
ルールのみより頑健ですが、計算負荷は大きくなります。
6.3 ニューラルネットワークベースVAD(現代の標準)
深層学習アーキテクチャを用います。
- CNN / RNN / Transformer
- 大規模かつ雑音の多いデータで学習
- 多様な環境で高い頑健性
現代的なVADの例:
- WebRTC VAD — リアルタイム通信で広く利用
- Silero VAD — 多言語対応の高性能ニューラルVAD
精度と頑健性の面で、ニューラルVADは本番システムの標準となっています。
7. ASRシステムにおけるVAD
現代のASRパイプラインでは、多くの場合、認識の前にVADを適用します。
音声 → VAD → 発話区間 → ASRモデル → 転写
利点は次のとおりです。
- 発話区間のみ処理してASR推論時間を短縮
- 雑音干渉を避けデコーディングを安定化
- 長尺ファイルの分割による並列処理
VADはゲートの役割を果たし、計算コストの高いASRモデルには関連区間だけを送ります。
8. VADとタイムスタンプ整合
各発話区間は元の開始・終了時刻を保持します。転写後、区間レベルのタイムスタンプを全体タイムラインに写し戻すことで、次が正確になります。
- タイミングの正確な字幕
- 動画編集などの音声—テキスト整合
- 話者ダイアライゼーションとセグメンテーション
音声とテキストの厳密な同期が必要な用途では、タイムスタンプ保持が不可欠です。
9. 実務上の考慮
挙動に効く主なパラメータは次のとおりです。
- フレーム長 — 各フレームの長さ(多くは10〜30 ms)
- 発話確率閾値 — 発話とみなす最小確率
- 最小発話継続時間 — 許容する最短発話区間
- 最小無音継続時間 — 区間終了とみなす無音の長さ
- パディング長 — 区間前後に付けるマージン
用途に応じて調整します。
- 会議:無音許容を長め、複数話者
- ポッドキャスト:明瞭な発話、背景雑音が少ない
- コールセンター:雑音環境、音質のばらつき
適切なチューニングがVAD性能に直結します。
まとめ
音声活動検出は音声処理の基盤です。発話が起きているタイミングを正確に捉えることで、ASRなど下流モデルをより効率的かつ高精度・高信頼で動かせます。
本番級の音声システムでは、VADはオプションではなく必須です。現代のニューラルVADは頑健性と精度で大きく前進しました。音声技術の進化とともに、パイプライン全体の性能を支える重要な前処理としてVADの役割は続きます。
