音声テキスト化の仕組みと精度に影響する要因
2025-11-27ドキュメント

Eric King
Author
はじめに
Speech-to-Text(STT)、別名 自動音声認識(ASR)は、話し言葉を書き言葉に変換します。最新の AI は非常に高精度ですが、転写の品質はパイプライン全体のさまざまな要因に左右されます。本記事では STT の流れ と 効き方に関わる主な要素 に焦点を当てます。
Speech-to-Text(STT)、別名 自動音声認識(ASR)は、話し言葉を書き言葉に変換します。最新の AI は非常に高精度ですが、転写の品質はパイプライン全体のさまざまな要因に左右されます。本記事では STT の流れ と 効き方に関わる主な要素 に焦点を当てます。
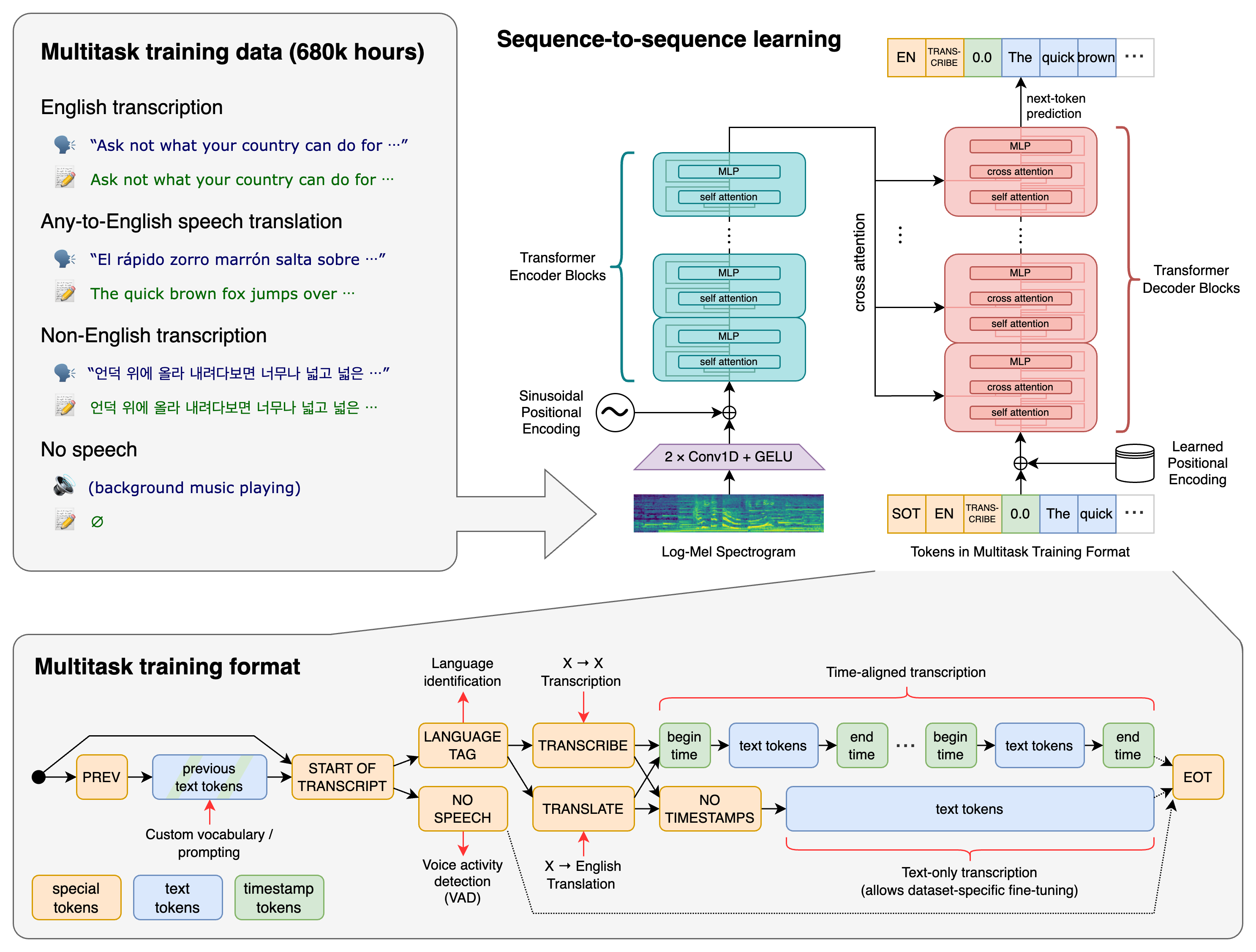
STT のワークフロー
STT は次のような段階に分けられます。
音声入力 → 前処理 → 特徴抽出 → 音響モデル → 言語モデル → デコーディング → 後処理 → テキスト出力
各段階が転写品質に重要です。
1. 音声入力
- ソース: マイク、アップロードした録音、ライブストリーム。
- 品質要因: 背景ノイズが少ないクリアな音声ほど認識が安定します。
- サンプリングレートと形式: 高いレート(例: 16–48 kHz)は音声の細部を残し、特徴抽出を助けます。
精度への影響: 録音機器やファイル品質が低いと音の忠実度が落ち、下流で誤りが増えます。
2. 前処理
- ノイズ低減: モデルを惑わせる背景音を抑えます。
- 正規化: 録音全体で音量レベルを揃えます。
- 分割(フレーミング): 音声を短いフレーム(多くは 20–40 ms)に切って順次処理します。
精度への影響: 前処理が不十分だとノイズ・残響・音量のばらつきが信号を歪め、認識品質が下がります。
3. 特徴抽出
- 音声フレームをモデル用の数値表現(特徴量)に変換します。
- 代表的な特徴:
- MFCC(メル周波数ケプストラム係数): 重要な周波数成分を捉えます。
- スペクトログラム: 時間と周波数方向のエネルギー分布を表します。
- 任意: ピッチ、エネルギー、デルタ係数など。
精度への影響: 特徴が音声特性を十分に表さないと、特に早口や訛りで音響モデルが音素を誤解釈しやすくなります。
4. 音響モデリング
- 特徴を 音素や文字 に対応づけます。
- 現代的な構成:
- RNN/LSTM/GRU: 時間方向の系列を扱います。
- CNN: 局所的な周波数パターンを捉えます。
- Transformer: 音声の長距離コンテキストをモデル化します。
精度への影響: モデル規模、学習データの多様性、ノイズ耐性が、発音やアクセントのばらつきにどれだけ追随できるかを決めます。
5. 言語モデリング
- 文脈・文法・語彙に基づき単語列を予測します。
- 同音異義語の区別や曖昧な音素の解消に役立ちます。
精度への影響: 言語モデルが弱いと、音素認識が合っていても文として不自然・誤った出力になり得ます。
6. デコーディング
- 音響モデルと言語モデルの出力を統合して最終テキストを生成します。
- 手法の例:
- CTC(Connectionist Temporal Classification): 音声フレームと予測テキストをアライメントします。
- ビームサーチ: より確からしい単語列を選びます。
精度への影響: デコーディングが不適切だと、特に早口や声の重なりで音声とテキストの対応がずれます。
7. 後処理
- 句読点、大文字化、書式(数値・日付・通貨など)を付与します。
- ドメイン固有の補正を入れると読みやすさと実用精度が上がります。
精度への影響: 後処理を省くと、音素レベルでは正しくても文章として分かりにくい出力になります。
STT 性能に効く主な要因
- 音質: クリアで高忠実度の録音が前提です。
- 背景ノイズ: 音楽・雑踏・環境音は精度を下げます。
- 話者のばらつき: アクセント、話速、イントネーションが認識に影響します。
- 語彙とドメイン: 専門用語・スラング・希少語は誤認されやすいです。
- モデル学習: 多様なデータで学習したモデルはアクセントやノイズに強くなります。
- 区切りと無音: 発話・無音・複数話者を適切に分けると転写の明瞭さが上がります。
要するに STT の精度は単一コンポーネントでは決まらず、音質・前処理・特徴・モデル・後処理の相互作用で決まります。
まとめ
Speech-to-Text AI は、音声をテキストに変える多段のパイプラインです。流れを理解すると、誤りの理由と改善の打ち手が見えやすくなります。高品質な音声、効いた前処理、頑健なモデル、丁寧な後処理 に寄せると、開発者も利用者も、より正確で信頼できる文字起こしに近づけます。
要点: STT の効きは 技術的パイプラインと入力品質の両方 に依存します。どれだけ高度なモデルでも、きれいで整理された音声があってこそ最高の性能を発揮します。