음성-텍스트 변환 원리와 정확도에 영향을 주는 요소
2025-11-27문서

Eric King
Author
서론
Speech-to-Text(STT), 즉 자동 음성 인식(ASR)은 말로 된 언어를 글자로 바꿉니다. 최신 AI는 매우 정확하지만, 전사 품질은 전체 파이프라인의 여러 요인에 달려 있습니다. 이 글에서는 STT가 어떻게 동작하는지와 효과에 영향을 주는 주요 요소를 다룹니다.
Speech-to-Text(STT), 즉 자동 음성 인식(ASR)은 말로 된 언어를 글자로 바꿉니다. 최신 AI는 매우 정확하지만, 전사 품질은 전체 파이프라인의 여러 요인에 달려 있습니다. 이 글에서는 STT가 어떻게 동작하는지와 효과에 영향을 주는 주요 요소를 다룹니다.
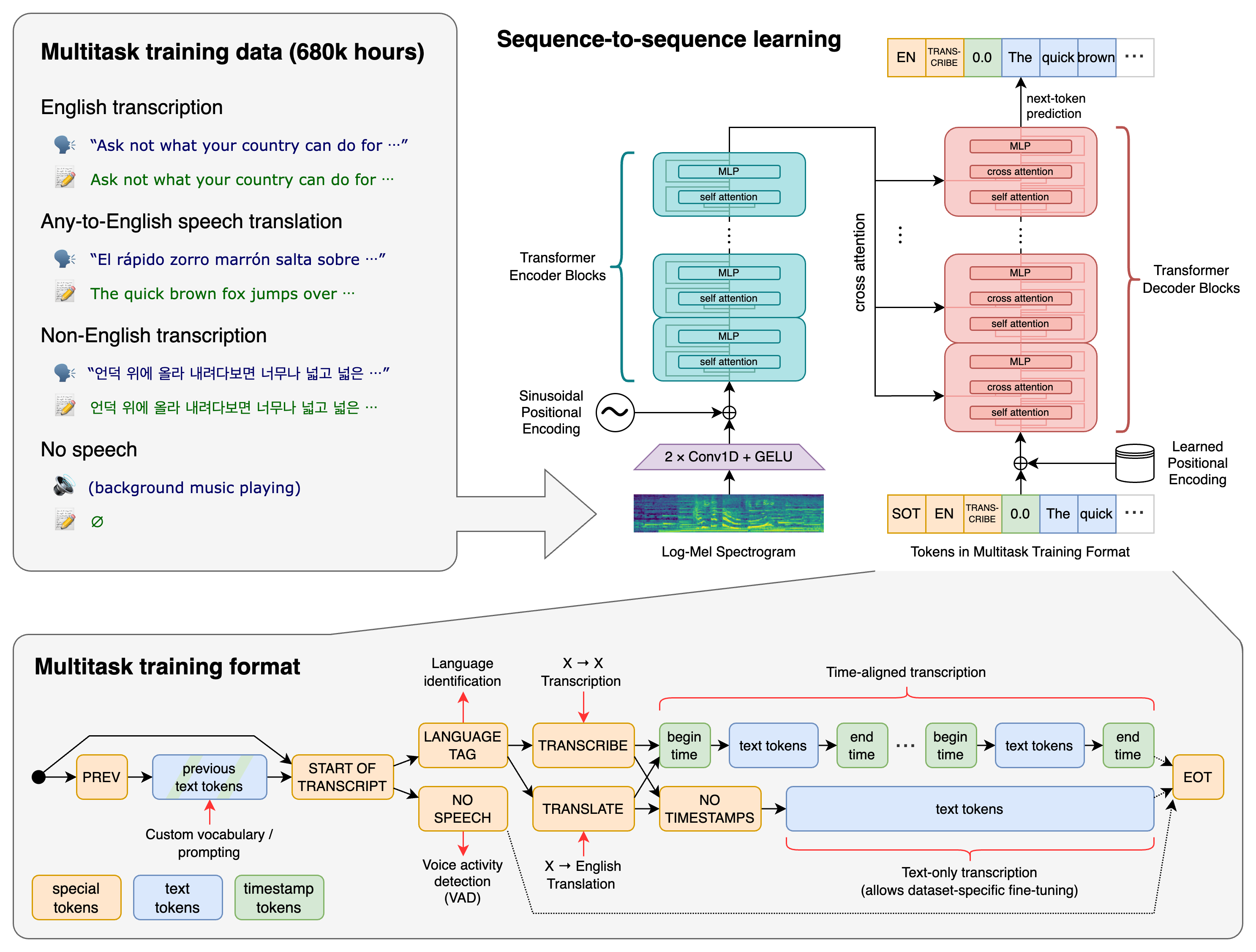
STT 워크플로
STT 과정은 여러 단계로 나눌 수 있습니다.
오디오 입력 → 전처리 → 특징 추출 → 음향 모델링 → 언어 모델링 → 디코딩 → 후처리 → 텍스트 출력
각 단계가 전사 품질에 중요합니다.
1. 오디오 입력
- 출처: 마이크, 업로드한 녹음, 라이브 스트림.
- 품질 요인: 배경 소음이 적고 맑은 오디오일수록 인식이 좋아집니다.
- 샘플링 레이트와 포맷: 높은 레이트(예: 16–48 kHz)는 음성 디테일을 보존해 특징 추출에 도움이 됩니다.
정확도에 미치는 영향: 녹음 장치나 파일 품질이 낮으면 음향 신호가 손상되어 이후 단계에서 오류가 늘어납니다.
2. 전처리
- 잡음 제거: 모델을 혼란스럽게 하는 배경 소음을 줄입니다.
- 정규화: 녹음 전체에서 볼륨 수준을 일정하게 맞춥니다.
- 분할(프레이밍): 오디오를 짧은 프레임(보통 20–40 ms)으로 나눠 순차 처리합니다.
정확도에 미치는 영향: 전처리가 부족하면 잡음, 잔향, 불균일한 볼륨이 신호를 왜곡해 인식 품질이 떨어집니다.
3. 특징 추출
- 오디오 프레임을 모델용 수치 표현(특징)으로 바꿉니다.
- 흔한 특징:
- MFCC(Mel 주파수 켑스트럼 계수): 중요한 주파수 성분을 담습니다.
- 스펙트로그램: 시간과 주파수에 따른 에너지 분포를 나타냅니다.
- 선택적 특징: 피치, 에너지, 델타 계수 등.
정확도에 미치는 영향: 특징이 음성 특성을 잘 반영하지 못하면, 특히 빠른 말이나 억양에서 음향 모델이 음소를 잘못 해석할 수 있습니다.
4. 음향 모델링
- 특징을 음소 또는 문자에 매핑합니다.
- 현대적 구조:
- RNN/LSTM/GRU: 시간적 연속을 포착합니다.
- CNN: 국소 주파수 패턴을 탐지합니다.
- Transformer: 음성의 장거리 문맥을 모델링합니다.
정확도에 미치는 영향: 모델 크기, 학습 데이터 다양성, 잡음 견고성이 발음·억양 변화를 얼마나 잘 따라가는지를 결정합니다.
5. 언어 모델링
- 문맥, 문법, 어휘를 바탕으로 단어 순서를 예측합니다.
- 동음이의어 구분과 모호한 음소 해소에 도움이 됩니다.
정확도에 미치는 영향: 언어 모델이 약하면 음소는 맞아도 문법적으로 틀리거나 무의미한 문장이 나올 수 있습니다.
6. 디코딩
- 음향 모델과 언어 모델 출력을 합쳐 최종 텍스트를 만듭니다.
- 기법 예:
- CTC(Connectionist Temporal Classification): 오디오 프레임과 예측 텍스트를 정렬합니다.
- 빔 서치: 더 그럴듯한 단어열을 고릅니다.
정확도에 미치는 영향: 디코딩이 잘못되면 특히 빠른 말이나 겹치는 목소리에서 오디오와 텍스트가 어긋날 수 있습니다.
7. 후처리
- 구두점, 대문자, 서식(숫자, 날짜, 통화 등)을 추가합니다.
- 도메인별 보정을 넣으면 가독성과 실사용 정확도가 올라갑니다.
정확도에 미치는 영향: 후처리를 생략하면 음소 수준에서는 맞아도 구조가 불명확한 텍스트가 될 수 있습니다.
STT 성능에 영향을 주는 핵심 요인
- 오디오 품질: 맑고 충실한 녹음이 필수입니다.
- 배경 소음: 음악, 군중, 환경 소음은 정확도를 낮춥니다.
- 화자 변동: 액센트, 말하기 속도, 억양이 인식에 영향을 줍니다.
- 어휘와 도메인: 전문 용어, 속어, 희귀 단어는 오인될 수 있습니다.
- 모델 학습: 다양한 데이터로 학습한 모델이 억양과 잡음에 더 강합니다.
- 분할과 침묵: 발화·침묵·다화자를 잘 구분하면 전사 명확도가 좋아집니다.
요약하면 STT 정확도는 한 구성 요소만으로 정해지지 않고, 오디오 품질·전처리·특징 추출·모델링·후처리의 상호작용으로 결정됩니다.
결론
Speech-to-Text AI는 오디오를 텍스트로 바꾸는 다단계 파이프라인입니다. 흐름을 이해하면 오류 원인과 최적화 방향을 잡기 쉬워집니다. 고품질 오디오, 효과적인 전처리, 견고한 모델링, 신중한 후처리에 집중하면 개발자와 사용자 모두 더 정확하고 신뢰할 수 있는 전사를 얻을 수 있습니다.
핵심: STT 효과는 기술 파이프라인과 입력 품질 모두에 달려 있습니다. 아무리 발전한 모델도 깨끗하고 잘 준비된 오디오가 있어야 최상의 성능을 냅니다.