Spraakactiviteitsdetectie (VAD)

Eric King
Author
Spraakactiviteitsdetectie (Voice Activity Detection, VAD) is een signaalverwerkingstechniek waarmee automatisch wordt bepaald of een audiosegment menselijke spraak of stilte/achtergrondruis bevat. In spraaksystemen werkt VAD als een voorverwerkingsstap die spraakgebieden scheidt van niet-spraak voordat vervolgstappen zoals automatische spraakherkenning (ASR), spraakvertaling of sprekeranalyse plaatsvinden.
1. Wat is spraakactiviteitsdetectie?
VAD is een fundamenteel onderdeel van moderne spraakverwerkingssystemen. Het voert een binaire classificatie uit: voor elk kort audioframe wordt bepaald of het spraak of niet-spraak (stilte, ruis, muziek, enz.) bevat.
Het kernprincipe is eenvoudig:
Audioframe → VAD-model → P(spraak)
Als de waarschijnlijkheid een vooraf vastgestelde drempel overschrijdt, wordt het frame als spraak geclassificeerd; anders als niet-spraak.
2. Waarom VAD belangrijk is
Ruwe audiosignalen bevatten vaak:
- Lange perioden van stilte
- Achtergrondruis
- Niet-spraakgeluiden (muziek, klikken, ademen)
Dergelijke audio direct naar ASR-modellen sturen leidt tot:
- Verspilde rekentijd bij het verwerken van stilte en ruis
- Lagere herkenningsnauwkeurigheid door ruisinterferentie
- Instabiele segmentatie en interpunctiefouten
- Hogere verwerkingskosten door onnodige berekeningen
Door niet-spraaksegmenten te verwijderen verbetert VAD de efficiëntie en nauwkeurigheid van downstream spraakmodellen aanzienlijk.
3. Typische VAD-verwerkingsketen
De VAD-pipeline volgt deze stappen:
- Ruwe audio →
- Framing (10–30 ms) →
- Kenmerkextractie →
- Schatting van spraakwaarschijnlijkheid →
- Temporele gladmaking →
- Generatie van spraaksegmenten
3.1 Framing
Het signaal wordt opgedeeld in korte overlappende frames (vaak 20 ms) om kortetermijnakoestische eigenschappen vast te leggen. Zo wordt audio in behapbare stukken geanalyseerd met behoud van temporele informatie door overlap.
3.2 Kenmerkextractie
Veelgebruikte kenmerken voor VAD:
- Kortetermijnenergie – meet het vermogen van het signaal
- Nulpassefrequentie – geeft de frequentie-inhoud aan
- Spectrale entropie – meet willekeurigheid in het frequentiedomein
- Log-Mel-filterbanken – in neurale VAD’s voor betere representatie
Ze helpen spraak van niet-spraak te onderscheiden via verschillende akoestische eigenschappen.
3.3 Schatting van spraakwaarschijnlijkheid
Een model (regelgebaseerd of neuraal netwerk) schat per frame de kans op spraak. Die wordt met een drempel vergeleken voor de eindbeslissing.
3.4 Temporele gladmaking
Frameniveau-beslissingen worden met temporele regels samengevoegd tot doorlopende spraaksegmenten:
- Een spraaksegment begint wanneer de waarschijnlijkheid gedurende een minimale duur boven de drempel blijft
- Een segment eindigt wanneer stilte langer duurt dan een vooraf vastgestelde stilteperiode
Zo wordt frequent wisselen tussen spraak en stilte door ruis of korte pauzes vermeden.
4. Van frames naar spraaksegmenten
Frameniveau-VAD-beslissingen moeten worden omgezet in doorlopende segmenten:
- Spraakaanvang: het segment start wanneer de waarschijnlijkheid gedurende een minimale duur boven de drempel blijft
- Spraakeinde: het segment eindigt wanneer stilte langer duurt dan een vooraf vastgestelde duur
Dit voorkomt fragmentatie door korte ruis of pauzes in echte spraak.
5. Padding en randcorrectie
Om begin en einde van spraak niet af te knippen, passen VAD-systemen meestal padding toe:
- Een kleine marge (bijv. 100–300 ms) vóór en na gedetecteerde segmenten
- Verbetert natuurlijkheid en herkenningsnauwkeurigheid
- Helpt volledige woorden en zinnen vast te leggen die anders gedeeltelijk worden afgesneden
Juiste padding voorkomt dat begin en einde worden afgekapt, cruciaal voor nauwkeurige transcriptie.
6. Soorten VAD-algoritmen
6.1 Regelgebaseerde VAD
Handgemaakte akoestische kenmerken en eenvoudige beslisregels:
- Voordelen: lichtgewicht en snel, geschikt voor omgevingen met beperkte middelen
- Nadelen: minder robuust bij ruis en wisselende akoestiek
Goed in gecontroleerde omgevingen; moeilijker in echte ruis.
6.2 Statistisch modelgebaseerde VAD
Probabilistische benaderingen:
- Gaussische mengmodellen (GMM) – modelleren de verdeling van spraak- en niet-spraakkenmerken
- Verborgen Markov-modellen (HMM) – vangen temporele afhankelijkheden tussen frames
Robuuster dan alleen regels, maar rekenintensiever.
6.3 Neuraal netwerk-gebaseerde VAD (moderne standaard)
Deep-learning-architecturen:
- CNN / RNN / Transformer
- Getraind op grote, ruisige datasets
- Zeer robuust in diverse omgevingen
Voorbeelden van moderne VAD:
- WebRTC VAD – veel gebruikt in realtimecommunicatie
- Silero VAD – hoogwaardige neurale VAD met meertalige ondersteuning
Neurale VAD is de productiestandaard vanwege nauwkeurigheid en robuustheid.
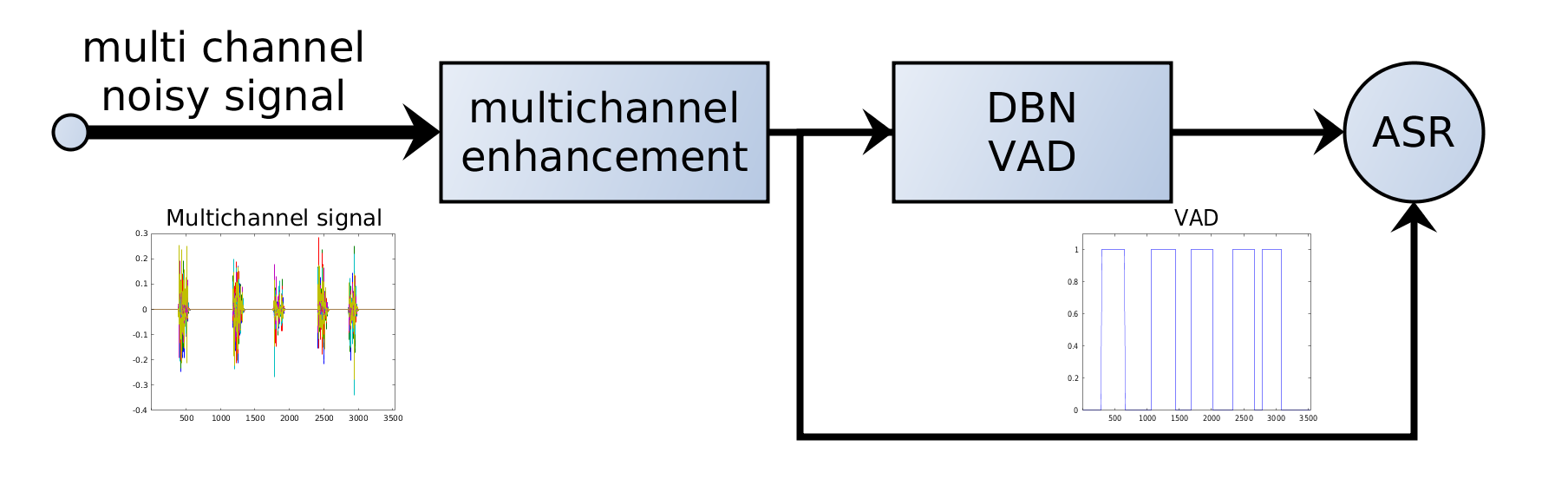
7. VAD in ASR-systemen
In moderne ASR-pipelines wordt VAD doorgaans vóór spraakherkenning toegepast:
Audio → VAD → spraaksegmenten → ASR-model → transcriptie
Voordelen:
- Kortere ASR-inferentietijd doordat alleen spraaksegmenten worden verwerkt
- Stabielere decodering door ruisinterferentie te vermijden
- Parallelle verwerking van lange bestanden door segmentatie
VAD werkt als poortwachter: alleen relevante segmenten gaan naar het rekenintensieve ASR-model.
8. VAD en tijdstempeluitlijning
Elk gedetecteerd segment behoudt de oorspronkelijke start- en eindtijd. Na transcriptie worden segmenttijdstempels teruggeprojecteerd op de globale tijdlijn, wat nauwkeurige:
- Ondertiteling met precieze timing mogelijk maakt
- Audio-tekstuitlijning voor videobewerking, enz.
- Sprekerdiarisatie en segmentatie ondersteunt
Het bewaren van tijdstempels is cruciaal wanneer audio en tekst nauwkeurig gesynchroniseerd moeten zijn.
9. Praktische overwegingen
Belangrijke parameters:
- Framelengte – duur van elk frame (typisch 10–30 ms)
- Drempel spraakwaarschijnlijkheid – minimale kans om als spraak te classificeren
- Minimale spraakduur – kortste toegestane spraaksegment
- Minimale stilteduur – stilte om een segment te beëindigen
- Paddinglengte – marge vóór en na spraaksegmenten
Afstemmen op het scenario:
- Vergaderingen: langere stiltetolerantie, meerdere sprekers
- Podcasts: duidelijke spraak, weinig achtergrondruis
- Callcenters: rumoerige omgevingen, wisselende audiokwaliteit
Juiste afstemming is essentieel voor optimale VAD-prestaties.
Conclusie
Spraakactiviteitsdetectie is een fundamenteel onderdeel van spraakverwerkingssystemen. Door nauwkeurig vast te stellen wanneer spraak optreedt, kunnen downstream-modellen zoals ASR efficiënter, nauwkeuriger en betrouwbaarder werken.
In productieklare spraaksystemen is VAD niet optioneel—het is essentieel. Moderne neurale VAD-systemen hebben grote vooruitgang geboekt in robuustheid en nauwkeurigheid. Naarmate spraaktechnologie evolueert, blijft VAD een kritieke voorverwerkingsstap voor optimale prestaties van de volledige pipeline.
