Hoe spraak-naar-tekst werkt en wat de nauwkeurigheid beïnvloedt
2025-11-27Documentatie

Eric King
Author
Inleiding
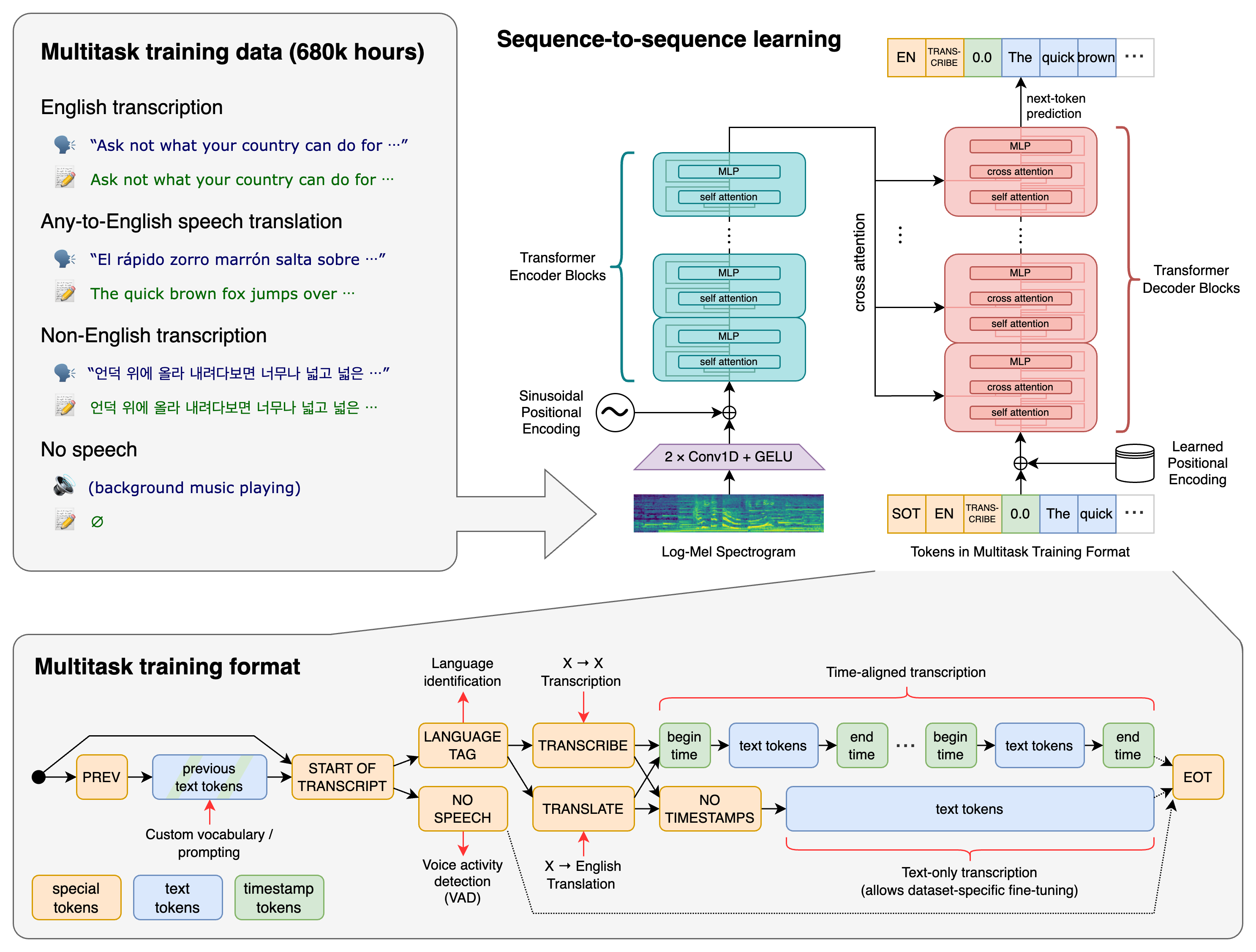
Spraak-naar-tekst (STT), ook automatische spraakherkenning (ASR) genoemd, zet gesproken taal om in geschreven tekst. Moderne AI-systemen zijn zeer nauwkeurig, maar de kwaliteit van de transcriptie hangt af van meerdere factoren in het hele proces. Dit artikel legt uit hoe STT werkt en welke elementen de effectiviteit beïnvloeden.
Spraak-naar-tekst (STT), ook automatische spraakherkenning (ASR) genoemd, zet gesproken taal om in geschreven tekst. Moderne AI-systemen zijn zeer nauwkeurig, maar de kwaliteit van de transcriptie hangt af van meerdere factoren in het hele proces. Dit artikel legt uit hoe STT werkt en welke elementen de effectiviteit beïnvloeden.
De STT-workflow
Het STT-proces bestaat uit verschillende fasen:
Audio-invoer → Voorbewerking → Feature-extractie → Akoestische modellering → Taalmodellering → Decodering → Nabewerking → Tekstuitvoer
Elke fase is belangrijk voor de transcriptiekwaliteit.
1. Audio-invoer
- Bron: Microfoons, geüploade opnames of livestreams.
- Kwaliteitsfactoren: Heldere audio met weinig achtergrondgeluid leidt tot betere herkenning.
- Bemonsteringsfrequentie en formaat: Hogere frequenties (bijv. 16–48 kHz) behouden spraakdetails en ondersteunen feature-extractie.
Effect op nauwkeurigheid: Slechte opnameapparatuur of lage bestandskwaliteit vermindert de geluidsgetrouwheid en veroorzaakt fouten verderop in de keten.
2. Voorbewerking
- Ruisonderdrukking: Verwijdert achtergrondruis die het model kan misleiden.
- Normalisatie: Zorgt voor consistente volumeniveaus in de opname.
- Segmentatie (framing): Verdeelt audio in korte vensters (meestal 20–40 ms) voor sequentiële verwerking.
Effect op nauwkeurigheid: Onvoldoende voorbewerking laat ruis, echo of ongelijk volume het signaal vervormen en verlaagt de herkenningskwaliteit.
3. Feature-extractie
- Zet audiobestanden om in numerieke representaties (features) voor het model.
- Veelgebruikte features:
- MFCC (Mel-frequentie-cepstrale coëfficiënten): Vangen belangrijke frequentiecomponenten.
- Spectrogrammen: Geven energieverdeling over tijd en frequentie weer.
- Optionele features: toonhoogte, energie of delta-coëfficiënten.
Effect op nauwkeurigheid: Als features de spraak slecht weergeven, kan het akoestische model fonemen verkeerd interpreteren, vooral bij snelle of geaccentueerde spraak.
4. Akoestische modellering
- Koppelt features aan fonemen of tekens.
- Moderne architecturen:
- RNN/LSTM/GRU: Vangen temporele sequenties.
- CNN: Detecteren lokale frequentiepatronen.
- Transformers: Modelleren langeafstandscontext in spraak.
Effect op nauwkeurigheid: Modelgrootte, diversiteit van trainingsdata en robuustheid tegen ruis bepalen hoe goed uitspraakvariatie en accenten worden herkend.
5. Taalmodellering
- Voorspelt woordreeksen op basis van context, grammatica en vocabulaire.
- Helpt bij homofonen en lost dubbelzinnige fonemen op.
Effect op nauwkeurigheid: Zwakke of beperkte taalmodellen kunnen grammaticaal foutieve of onzinzinnen produceren, zelfs als fonemen goed zijn herkend.
6. Decodering
- Combineert uitvoer van akoestisch en taalmodel tot de uiteindelijke tekst.
- Technieken:
- CTC (Connectionist Temporal Classification): Lijnt audioblokken af op voorspelde tekst.
- Beam search: Kiest waarschijnlijkste woordsequenties.
Effect op nauwkeurigheid: Onjuiste decodering kan audio en tekst uit de pas laten lopen, vooral bij snelle spraak of overlappende stemmen.
7. Nabewerking
- Voegt interpunctie, hoofdletters en opmaak toe (cijfers, datums, valuta).
- Optionele domeinspecifieke correcties verbeteren leesbaarheid en nauwkeurigheid.
Effect op nauwkeurigheid: Zonder nabewerking blijft tekst ongestructureerd of dubbelzinnig, ook als fonemniveau correct is.
Belangrijkste factoren voor STT-prestaties
- Audiokwaliteit: Heldere, getrouwe opnames zijn cruciaal.
- Achtergrondgeluid: Muziek, menigte of omgeving verlagen de nauwkeurigheid.
- Sprekervariatie: Accent, spreektempo en intonatie beïnvloeden herkenning.
- Vocabulaire en domein: Vakjargon, slang of zeldzame woorden kunnen verkeerd worden geïnterpreteerd.
- Modeltraining: Modellen getraind op diverse datasets zijn robuuster tegen accenten en ruis.
- Segmentatie en stilte: Spraak, stilte en meerdere sprekers goed scheiden verbetert de transcriptieduidelijkheid.
Kortom, STT-nauwkeurigheid wordt niet door één onderdeel bepaald, maar door het samenspel van audiokwaliteit, voorbewerking, feature-extractie, modellering en nabewerking.
Conclusie
Spraak-naar-tekst-AI is een meerfasige pijplijn van audio naar tekst. Inzicht in de workflow helpt fouten te verklaren en prestaties te verbeteren. Met hoogwaardige audio, effectieve voorbewerking, robuuste modellering en zorgvuldige nabewerking bereiken ontwikkelaars en gebruikers nauwkeurigere en betrouwbaardere transcripties.
Kerninzicht: STT-effectiviteit hangt zowel af van de technische pijplijn als van de invoerkwaliteit; zelfs de meest geavanceerde modellen hebben schone, goed gestructureerde audio nodig voor topprestaties.