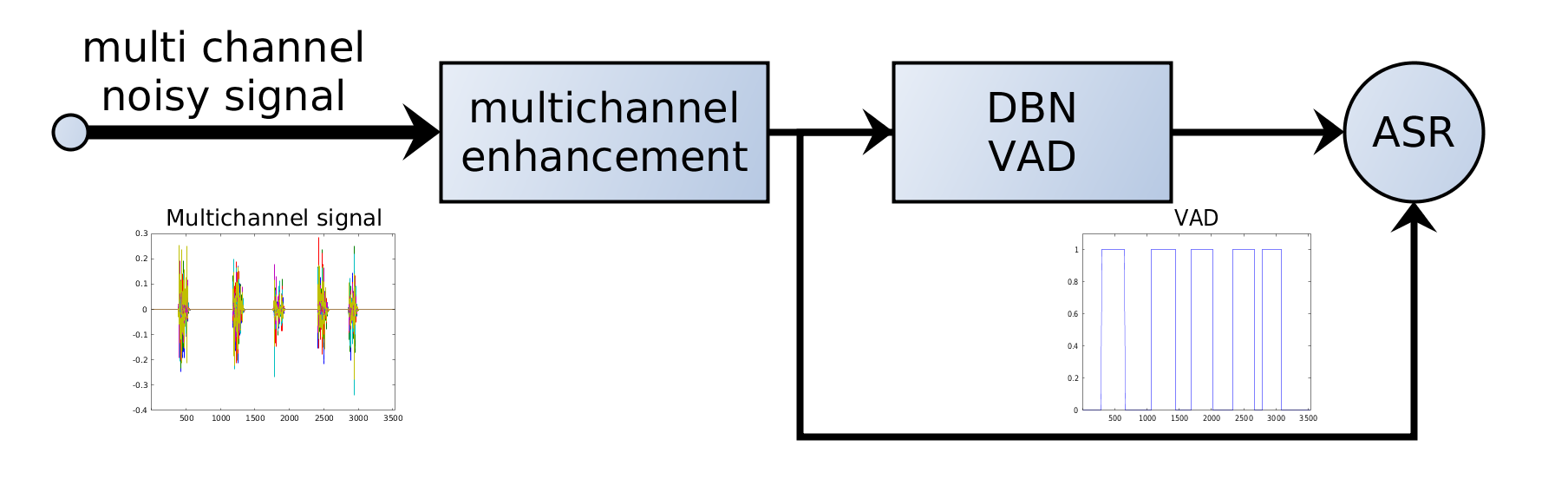
Deteção de atividade de voz (VAD)

Eric King
Author
A deteção de atividade de voz (Voice Activity Detection, VAD) é uma técnica de processamento de sinal usada para determinar automaticamente se um segmento de áudio contém fala humana ou silêncio/ruído de fundo. Em sistemas de voz, o VAD atua como etapa de pré-processamento que separa regiões de fala de regiões não verbais antes de passos posteriores como reconhecimento automático de fala (ASR), tradução de fala ou análise do locutor.
1. O que é a deteção de atividade de voz?
O VAD é um componente fundamental dos sistemas modernos de processamento de fala. Realiza uma classificação binária: para cada pequeno quadro de áudio decide se contém fala ou não fala (silêncio, ruído, música, etc.).
O princípio central é simples:
Quadro de áudio → modelo VAD → P(fala)
Se a probabilidade exceder um limiar pré-definido, o quadro é classificado como fala; caso contrário, como não fala.
2. Porque o VAD é importante
Sinais de áudio brutos frequentemente contêm:
- Longos períodos de silêncio
- Ruído de fundo
- Sons não verbais (música, cliques, respiração)
Enviar esse áudio diretamente a modelos ASR leva a:
- Computação desperdiçada ao processar silêncio e ruído
- Menor precisão de reconhecimento por interferência do ruído
- Segmentação instável e erros de pontuação
- Custos de processamento mais elevados por cálculos desnecessários
Ao remover segmentos não verbais, o VAD melhora de forma significativa a eficiência e a precisão dos modelos a jusante.
3. Pipeline típico de processamento VAD
O fluxo VAD segue estes passos:
- Áudio bruto →
- Enquadramento (10–30 ms) →
- Extração de características →
- Estimação da probabilidade de fala →
- Suavização temporal →
- Geração de segmentos de fala
3.1 Enquadramento
O sinal é dividido em pequenos quadros sobrepostos (comummente 20 ms) para capturar características acústicas de curto prazo. Permite analisar o áudio em blocos geríveis preservando informação temporal por sobreposição.
3.2 Extração de características
Características comuns em VAD:
- Energia de curto prazo – mede a potência do sinal
- Taxa de passagem por zero – indica o conteúdo em frequência
- Entropia espectral – mede a aleatoriedade no domínio da frequência
- Bancos de filtros log-Mel – em VAD neuronal para melhor representação
Ajudam a distinguir fala de não fala capturando propriedades acústicas diferentes.
3.3 Estimação da probabilidade de fala
Um modelo (baseado em regras ou rede neuronal) estima a probabilidade de cada quadro conter fala. A probabilidade é comparada a um limiar para a decisão final.
3.4 Suavização temporal
Decisões ao nível do quadro são fundidas em segmentos contínuos com regras temporais:
- Um segmento de fala começa quando a probabilidade permanece acima do limiar durante uma duração mínima
- Um segmento termina quando o silêncio persiste além de uma duração pré-definida
Evita comutações frequentes entre fala e silêncio por ruído ou pausas breves.
4. De quadros a segmentos de fala
As decisões VAD por quadro precisam ser convertidas em segmentos contínuos:
- Início de fala: o segmento começa quando a probabilidade permanece acima do limiar durante uma duração mínima
- Fim de fala: o segmento termina quando o silêncio excede uma duração pré-definida
Previne fragmentação por ruído breve ou pausas dentro da fala real.
5. Padding e ajuste de limites
Para não cortar inícios e fins de fala, os sistemas VAD aplicam normalmente padding:
- Uma pequena margem (p.ex. 100–300 ms) antes e depois dos segmentos detetados
- Melhora naturalidade e precisão do reconhecimento
- Ajuda a capturar palavras e frases completas que poderiam ficar parcialmente cortadas
Padding adequado evita truncar o início e o fim dos segmentos, crucial para transcrição precisa.
6. Tipos de algoritmos VAD
6.1 VAD baseado em regras
Usa características acústicas desenhadas manualmente e regras simples:
- Vantagens: leve e rápido, adequado a ambientes com recursos limitados
- Desvantagens: menos robusto ao ruído e a condições acústicas variáveis
Funciona bem em ambientes controlados; com ruído real é mais difícil.
6.2 VAD baseado em modelos estatísticos
Abordagens probabilísticas:
- Modelos de mistura gaussiana (GMM) – modelam a distribuição de características de fala e não fala
- Modelos ocultos de Markov (HMM) – captam dependências temporais entre quadros
Mais robustos que regras puras, mas exigem mais recursos computacionais.
6.3 VAD baseado em redes neuronais (padrão moderno)
Arquiteturas de aprendizagem profunda:
- CNN / RNN / Transformer
- Treinados em conjuntos grandes e ruidosos
- Alta robustez em ambientes diversos
Exemplos de VAD modernos:
- WebRTC VAD – muito usado em comunicação em tempo real
- Silero VAD – VAD neuronal de alto desempenho com suporte multilingue
O VAD neuronal tornou-se o padrão em produção pela precisão e robustez superiores.
7. VAD em sistemas ASR
Em pipelines ASR modernos, o VAD aplica-se tipicamente antes do reconhecimento:
Áudio → VAD → segmentos de fala → modelo ASR → transcrição
Benefícios:
- Reduz o tempo de inferência ASR ao processar apenas segmentos de fala
- Melhora a estabilidade da descodificação evitando interferência do ruído
- Permite processamento em paralelo de ficheiros longos por segmentação
O VAD age como filtro: apenas os segmentos relevantes vão para o modelo ASR dispendioso.
8. VAD e alinhamento de carimbos de data/hora
Cada segmento detetado conserva os tempos de início e fim originais. Após a transcrição, os carimbos por segmento são mapeados para a linha temporal global, garantindo:
- Legendagem com sincronização precisa
- Alinhamento áudio-texto para edição de vídeo, etc.
- Diarização de locutores e segmentação
A preservação dos carimbos é crucial quando é necessária sincronização precisa entre áudio e texto.
9. Considerações práticas
Parâmetros-chave:
- Comprimento do quadro – duração de cada quadro (tipicamente 10–30 ms)
- Limiar de probabilidade de fala – probabilidade mínima para classificar como fala
- Duração mínima de fala – segmento de fala mais curto permitido
- Duração mínima de silêncio – silêncio para terminar um segmento
- Comprimento do padding – margem antes e depois dos segmentos
Devem ser afinados ao cenário:
- Reuniões: maior tolerância ao silêncio, vários locutores
- Podcasts: fala clara, pouco ruído de fundo
- Centros de contacto: ambientes ruidosos, qualidade de áudio variável
A afinação correta é essencial para um desempenho VAD ótimo.
Conclusão
A deteção de atividade de voz é um componente fundamental do processamento de fala. Ao detetar com precisão quando há fala, permite que modelos a jusante como o ASR operem de forma mais eficiente, precisa e fiável.
Em sistemas de nível de produção, o VAD não é opcional: é essencial. Os sistemas VAD neuronais modernos avançaram muito em robustez e precisão. À medida que a tecnologia de fala evolui, o VAD permanecerá um passo de pré-processamento crítico para o desempenho ótimo de toda a pipeline.
