Entender o Whisper: guia completo ao modelo de reconhecimento de fala da OpenAI

Eric King
Author
Introdução
O Whisper da OpenAI é um modelo avançado de reconhecimento automático de fala (ASR) feito para converter áudio falado em texto preciso e legível. Lançado como projeto de código aberto, o Whisper tornou-se rapidamente uma das tecnologias de transcrição mais adotadas graças ao suporte multilíngue, robustez a ruído e flexibilidade em cenários reais.
Este artigo oferece uma visão clara e orientada a SEO de como o Whisper funciona, o que o torna único, seus pontos fortes e limitações, e como se compara a outros grandes modelos ASR do setor.
O que é o Whisper?
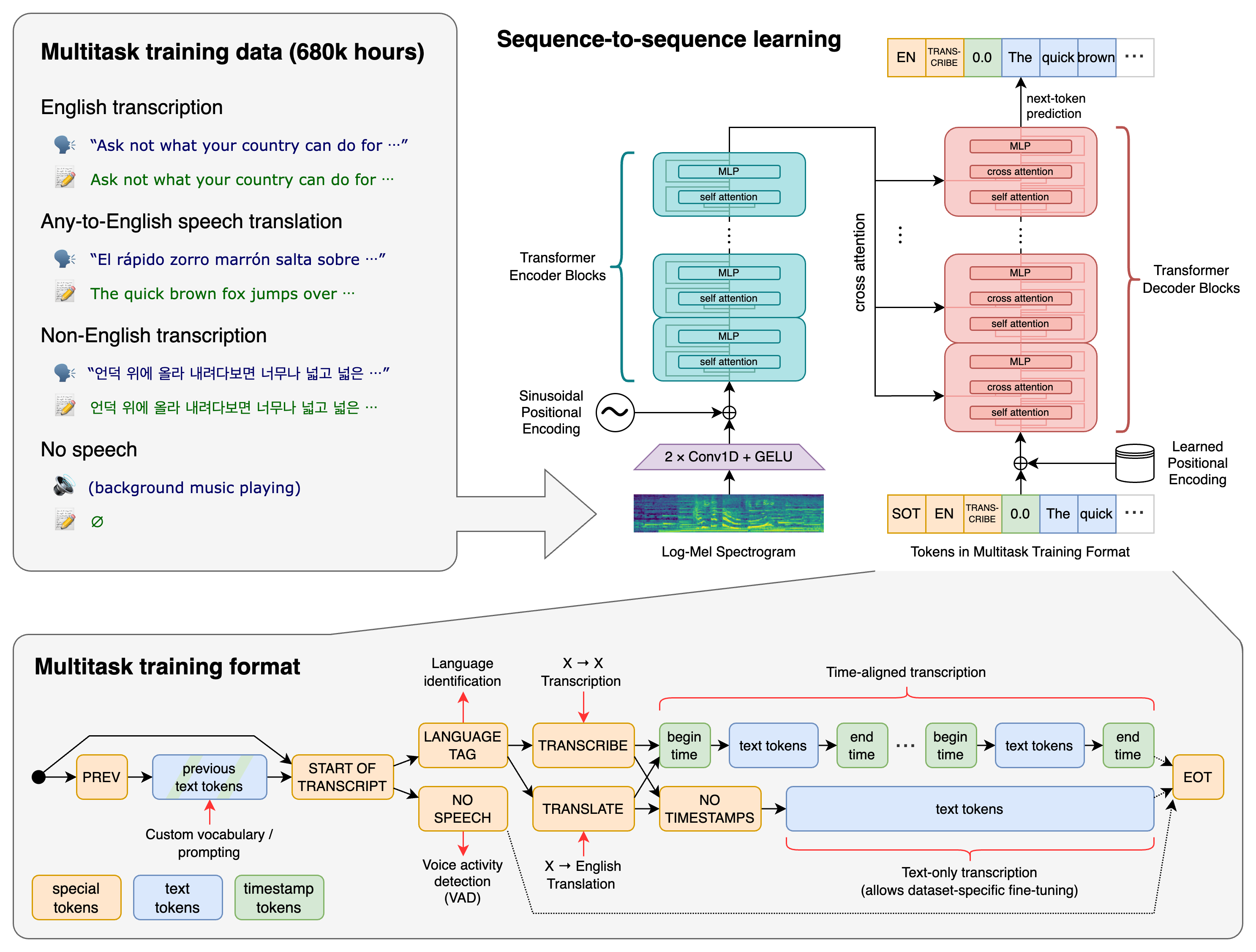
O Whisper é um sistema ASR de aprendizado profundo treinado com 680.000 horas de dados supervisionados multilíngues e multitarefa coletados na web. O treinamento inclui diversos sotaques, condições de ruído e qualidades de áudio — tornando-o muito mais robusto que muitos modelos convencionais.
Principais tarefas suportadas:
- Transcrição fala para texto
- Tradução de fala (áudio → texto em inglês)
- Identificação de idioma
- Geração de carimbos de tempo
- Transcrição multilíngue
Por ser código aberto, desenvolvedores podem executá-lo localmente, ajustar fluxos de trabalho ou integrá-lo a aplicações sem depender de APIs de terceiros.
Recursos principais do Whisper
1. Reconhecimento multilíngue
O Whisper suporta quase 100 idiomas, ideal para aplicações globais e bases de usuários diversas.
2. Alta robustez a ruído
Graças a dados de treino em larga escala, o Whisper lida com:
- Ruído de fundo
- Fala sobreposta
- Reverberação
- Microfones de baixa qualidade
Adequado para áudio real: reuniões, entrevistas e gravações móveis.
3. Carimbos de tempo no nível da palavra
O Whisper (e extensões como WhisperX) podem gerar carimbos precisos para:
- Legendas
- Segmentação de podcasts
- Fluxos de legendagem de vídeo
4. Capacidades de tradução
O Whisper pode traduzir áudio não inglês diretamente para texto em inglês sem um modelo de tradução separado.
5. Totalmente código aberto
Pode ser implantado em:
- Servidores on-premise
- VMs na nuvem
- Desktops locais com GPU
- Dispositivos de borda
Código aberto significa controle total sobre custo, privacidade e personalização.
Variantes do modelo Whisper
| Tamanho | Velocidade | Precisão | Caso de uso |
|---|---|---|---|
| Tiny | Mais rápido | Mais baixa | Tempo real, dispositivos móveis |
| Base | Muito rápido | Baixa–média | Transcrições rápidas |
| Small | Equilibrado | Média | Tarefas gerais |
| Medium | Mais lento | Alta | Transcrição profissional |
| Large | Mais lento | Máxima | Máxima precisão, multilíngue |
A escolha costuma depender de computação e requisitos de precisão.
Pontos fortes do Whisper
- Alta precisão mesmo em condições difíceis
- Melhor tratamento de sotaques e dialetos que muitos ASR comerciais
- Suporte multilíngue nativo
- Código aberto (sem lock-in de fornecedor, personalizável)
- Carimbos de tempo e segmentação
Limitações do Whisper
- Exige GPU considerável para maior velocidade
- Modelos grandes podem ser lentos em CPU
- Pode alucinar pequenos trechos de não-fala em áudio muito ruidoso
- Não otimizado para tarefas de fala altamente estruturadas (ex.: regras de pontuação por idioma)
Forks otimizados como Faster-Whisper, WhisperX ou quantização em GPU costumam mitigar essas limitações.
Whisper vs outros modelos ASR
Comparação orientada a SEO entre o Whisper e outros sistemas ASR conhecidos:
Tabela comparativa ASR
| Recurso / modelo | OpenAI Whisper | Google Speech-to-Text | Amazon Transcribe | Microsoft Azure STT | Deepgram |
|---|---|---|---|---|---|
| Código aberto | Sim | Não | Não | Não | Parcial (apenas SDK) |
| Multilíngue | Excelente | Bom | Médio | Bom | Médio |
| Robustez a ruído | Muito forte | Moderada | Média | Média | Forte |
| Carimbos de tempo | Sim | Sim | Sim | Sim | Sim |
| Tempo real | Limitado (depende do hardware) | Sim | Sim | Sim | Sim |
| Custo | Grátis (self-hosted) | Pago | Pago | Pago | Pago |
| Personalização | Total (open source) | Limitada | Limitada | Limitada | Média |
| Precisão | Alta | Alta | Alta | Alta | Alta |
Resumo:
O Whisper se destaca pela abertura, vantagem de custo e robustez a ruído. ASRs em nuvem se saem bem em baixa latência em tempo real; o Whisper oferece mais flexibilidade e privacidade.
Extensões populares do Whisper
1. Faster-Whisper
Implementação otimizada com CTranslate2. Benefícios:
- Inferência 2–4× mais rápida
- Menor uso de memória
- Suporte a quantização (int8/int16)
Ideal para servidores de produção.
2. WhisperX
Estende o Whisper com:
- Alinhamento no nível da palavra
- Carimbos de tempo mais precisos
- Diarização de falantes (via Pyannote)
Perfeito para legendas, podcasts e transcrição de mídia.
3. Distil-Whisper
Versão destilada, menor e mais rápida, com perda mínima de precisão.
Quando usar o Whisper?
O Whisper é ideal se você precisa de:
- transcrição de alta precisão
- áudio multilíngue
- implantações focadas em privacidade
- pipelines personalizáveis
- ASR em larga escala e econômico
- transcrição offline ou no dispositivo
Se a latência for a prioridade máxima, o ASR em nuvem ainda pode ser melhor.
Conclusão
O Whisper representa um dos avanços mais importantes em reconhecimento de fala de código aberto. Desempenho sólido, multilíngue e flexibilidade o tornam uma ferramenta poderosa para desenvolvedores, pesquisadores e empresas que constroem aplicações de transcrição ou tradução.
Com a inovação contínua da comunidade — WhisperX, Faster-Whisper — o ecossistema Whisper continua a crescer e é uma excelente escolha para fluxos ASR modernos.
