Детекция голосовой активности (VAD)

Eric King
Author
Детекция голосовой активности (Voice Activity Detection, VAD) — это метод обработки сигналов, который автоматически определяет, содержит ли фрагмент аудио человеческую речь или тишину/фоновый шум. В речевых системах VAD выполняет роль этапа предобработки: отделяет области речи от неречевых перед дальнейшими шагами — например, автоматическим распознаванием речи (ASR), переводом речи или анализом говорящего.
1. Что такое детекция голосовой активности?
VAD — базовый компонент современных систем обработки речи. Он решает задачу бинарной классификации: для каждого короткого аудиокадра определяется, содержит ли кадр речь или неречь (тишина, шум, музыка и т. д.).
Принцип прост:
Аудиокадр → модель VAD → P(речь)
Если вероятность выше заранее заданного порога, кадр классифицируется как речь; иначе — как неречь.
2. Зачем нужен VAD
В сыром аудио часто есть:
- Длительные участки тишины
- Фоновый шум
- Неречевые звуки (музыка, щелчки, дыхание)
Подача такого аудио напрямую в модели ASR приводит к:
- Лишним вычислениям на тишине и шуме
- Снижению точности распознавания из‑за помех
- Нестабильной сегментации и ошибкам пунктуации
- Росту стоимости обработки из‑за лишних расчётов
Удаляя неречевые сегменты, VAD заметно повышает эффективность и точность последующих речевых моделей.
3. Типичный конвейер обработки VAD
Цепочка VAD обычно включает:
- Исходное аудио →
- Разбиение на кадры (10–30 мс) →
- Извлечение признаков →
- Оценка вероятности речи →
- Временное сглаживание →
- Формирование речевых сегментов
3.1 Разбиение на кадры
Сигнал делится на короткие перекрывающиеся кадры (часто 20 мс), чтобы уловить кратковременные акустические свойства. Так анализ идёт по управляемым фрагментам, а перекрытие сохраняет временную информацию.
3.2 Извлечение признаков
Распространённые признаки для VAD:
- Кратковременная энергия — мощность сигнала
- Частота пересечения нуля — о содержании по частоте
- Спектральная энтропия — «случайность» в частотной области
- Лог‑мел‑фильтробанки — в нейросетевых VAD для лучшего представления
Они помогают отличать речь от неречи по разным акустическим свойствам.
3.3 Оценка вероятности речи
Модель (правила или нейросеть) оценивает вероятность речи в каждом кадре. Она сравнивается с порогом для финального решения.
3.4 Временное сглаживание
Решения по кадрам объединяются в непрерывные речевые сегменты по временным правилам:
- Сегмент речи начинается, когда вероятность речи держится выше порога минимально допустимое время
- Сегмент заканчивается, когда тишина длится дольше заданной длительности
Так реже происходит «дрожание» между речью и тишиной из‑за шума или коротких пауз.
4. От кадров к речевым сегментам
Кадровые решения VAD нужно превратить в непрерывные сегменты:
- Начало речи: сегмент стартует, когда вероятность речи удерживается выше порога минимальное время
- Конец речи: сегмент завершается, когда тишина превышает заданную длительность
Это снижает фрагментацию из‑за краткого шума или пауз внутри реальной речи.
5. Отступы (padding) и границы
Чтобы не обрезать начало и конец речи, обычно добавляют padding:
- Небольшой запас (например, 100–300 мс) до и после обнаруженных сегментов
- Улучшает естественность и точность распознавания
- Помогает захватить целые слова и фразы, которые иначе могли бы обрезаться
Корректный padding важен для точной транскрипции.
6. Типы алгоритмов VAD
6.1 Правило‑ориентированный VAD
Ручные акустические признаки и простые правила:
- Плюсы: лёгкий и быстрый, подходит для ограниченных ресурсов
- Минусы: хуже переносит шум и меняющиеся акустические условия
Хорошо в контролируемых средах; в реальном шуме слабее.
6.2 VAD на статистических моделях
Вероятностные подходы:
- Смеси гауссовых распределений (GMM) — моделируют распределения признаков речи и неречи
- Скрытые марковские модели (HMM) — учитывают временные зависимости между кадрами
Робастнее чистых правил, но тяжелее по вычислениям.
6.3 Нейросетевой VAD (современный стандарт)
Архитектуры глубокого обучения:
- CNN / RNN / Transformer
- Обучение на больших зашумлённых данных
- Высокая устойчивость в разных условиях
Примеры современных VAD:
- WebRTC VAD — широко в реальном времени
- Silero VAD — производительный нейросетевой VAD с мультиязычной поддержкой
Нейросетевой VAD стал стандартом в продакшене за счёт точности и устойчивости.
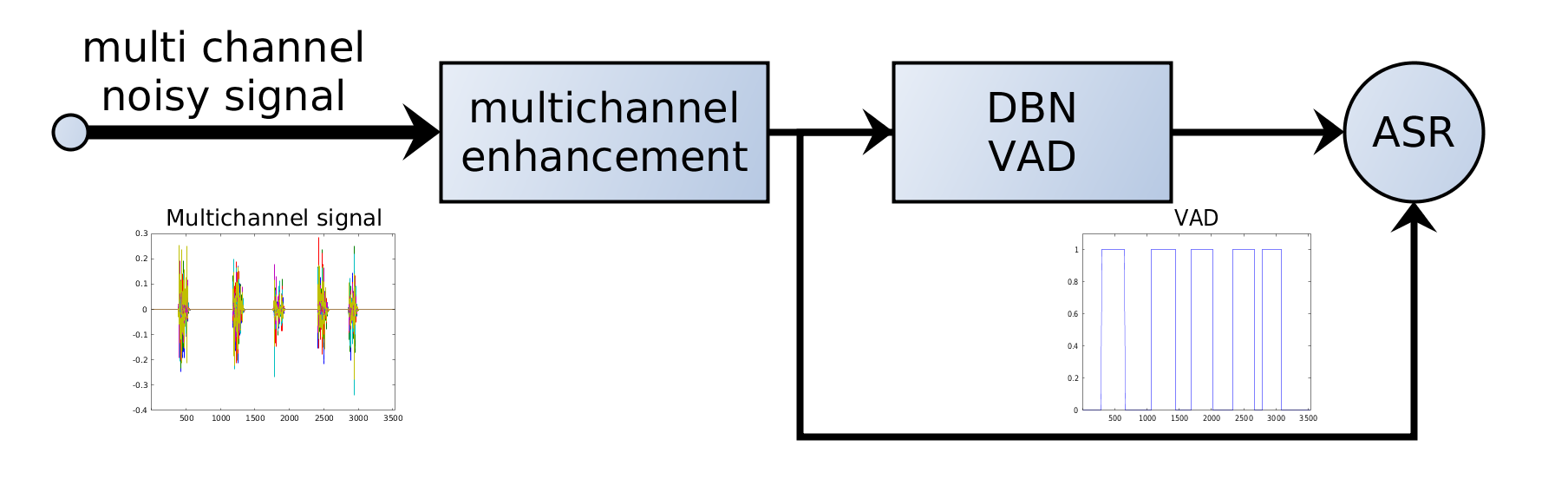
7. VAD в системах ASR
В современных ASR‑конвейерах VAD обычно применяют до распознавания:
Аудио → VAD → речевые сегменты → модель ASR → транскрипт
Плюсы:
- Меньше время инференса ASR — обрабатываются только речевые сегменты
- Стабильнее декодирование — меньше влияния шума
- Параллельная обработка длинных файлов за счёт сегментации
VAD работает как фильтр: в тяжёлую модель ASR попадают только релевантные участки.
8. VAD и выравнивание по времени
У каждого сегмента сохраняются исходные время начала и конца. После транскрипции метки сегментов отображаются на общую шкалу времени — это нужно для:
- Субтитров с точной синхронизацией
- Выравнивания аудио и текста (монтаж и др.)
- Диаризации и сегментации говорящих
Сохранение временных меток критично, когда нужна точная синхронизация аудио и текста.
9. Практические замечания
Ключевые параметры:
- Длина кадра — обычно 10–30 мс
- Порог вероятности речи — минимум для класса «речь»
- Минимальная длительность речи — кратчайший допустимый сегмент
- Минимальная длительность тишины — когда сегмент завершается
- Длина padding — поля до и после сегментов
Настраиваются под сценарий:
- Встречи: большая толерантность к тишине, несколько говорящих
- Подкасты: чистая речь, мало фона
- Колл‑центры: шум, нестабильное качество
Правильная настройка важна для качества VAD.
Заключение
Детекция голосовой активности — фундаментальная часть обработки речи. Точно определяя моменты речи, она позволяет downstream‑моделям, таким как ASR, работать эффективнее, точнее и надёжнее.
В промышленных системах VAD не опция — он необходим. Современные нейросетевые VAD сильно выросли в устойчивости и точности. По мере развития речевых технологий VAD останется критическим шагом предобработки для оптимальной работы всего конвейера.
