Как работает распознавание речи (speech-to-text) и от чего зависит точность
2025-11-27Документация

Eric King
Author
Введение
Преобразование речи в текст (STT), или автоматическое распознавание речи (ASR), переводит устную речь в письменный текст. Современные ИИ-системы очень точны, но качество транскрипции зависит от множества факторов на всём пути обработки. Статья рассказывает, как устроен STT и какие элементы влияют на его эффективность.
Преобразование речи в текст (STT), или автоматическое распознавание речи (ASR), переводит устную речь в письменный текст. Современные ИИ-системы очень точны, но качество транскрипции зависит от множества факторов на всём пути обработки. Статья рассказывает, как устроен STT и какие элементы влияют на его эффективность.
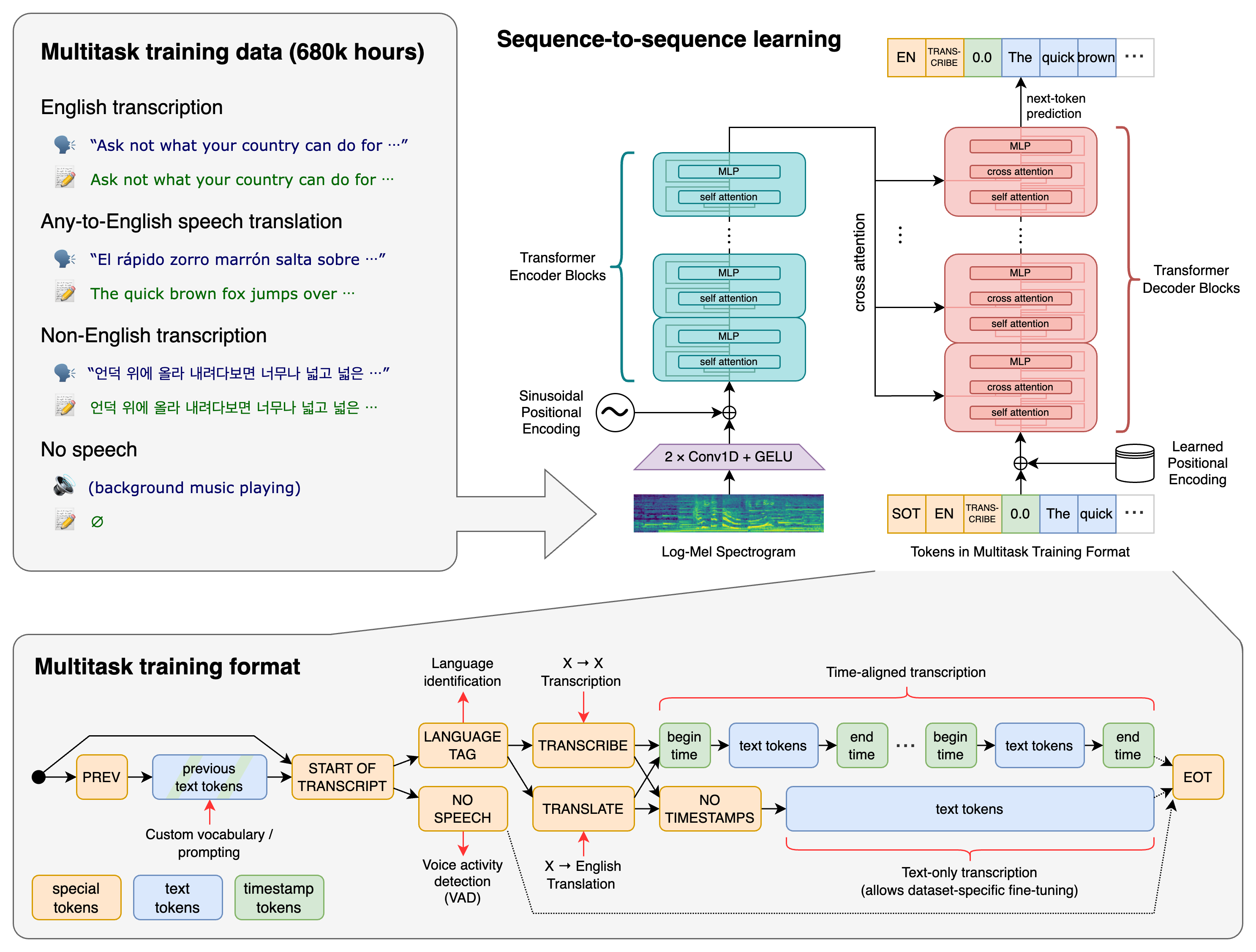
Конвейер STT
Процесс STT можно разделить на этапы:
Ввод аудио → Предобработка → Извлечение признаков → Акустическое моделирование → Языковое моделирование → Декодирование → Постобработка → Текст на выходе
Каждый этап важен для качества транскрипции.
1. Ввод аудио
- Источник: Микрофоны, загруженные записи или прямые трансляции.
- Качество: Чистый звук с малым фоновым шумом улучшает распознавание.
- Частота дискретизации и формат: Более высокие частоты (например, 16–48 кГц) сохраняют детали речи и помогают извлечению признаков.
Влияние на точность: Слабые записывающие устройства или низкокачественные файлы снижают достоверность сигнала и приводят к ошибкам на следующих шагах.
2. Предобработка
- Шумоподавление: Убирает фоновый шум, который может сбивать модель.
- Нормализация: Выравнивает уровень громкости по всей записи.
- Сегментация (кадрирование): Делит аудио на короткие окна (обычно 20–40 мс) для последовательной обработки.
Влияние на точность: Недостаточная предобработка позволяет шуму, эхо или неравномерной громкости искажать сигнал и снижает качество распознавания.
3. Извлечение признаков
- Преобразует аудиоокна в числовые представления (признаки) для модели.
- Распространённые признаки:
- MFCC (мел-частотные кепстральные коэффициенты): Отражают важные частотные компоненты.
- Спектрограммы: Показывают распределение энергии по времени и частоте.
- Дополнительно: высота тона, энергия или дельта-коэффициенты.
Влияние на точность: Если признаки плохо отражают речь, акустическая модель может неверно интерпретировать фонемы, особенно при быстрой речи или акценте.
4. Акустическое моделирование
- Сопоставляет признаки с фонемами или символами.
- Современные архитектуры:
- RNN/LSTM/GRU: Улавливают временные последовательности.
- CNN: Выявляют локальные частотные шаблоны.
- Трансформеры: Моделируют дальний контекст в речи.
Влияние на точность: Размер модели, разнообразие обучающих данных и устойчивость к шуму определяют, насколько хорошо распознаются вариации произношения и акценты.
5. Языковое моделирование
- Предсказывает последовательности слов с учётом контекста, грамматики и словаря.
- Помогает различать омофоны и снимать неоднозначность фонем.
Влияние на точность: Слабые или ограниченные языковые модели могут давать грамматически неверные или бессмысленные предложения даже при верных фонемах.
6. Декодирование
- Объединяет выходы акустической и языковой моделей в итоговый текст.
- Методы:
- CTC (Connectionist Temporal Classification): Сопоставляет аудиоокна с предсказанным текстом.
- Поиск с отсечением луча (beam search): Выбирает наиболее вероятные цепочки слов.
Влияние на точность: Неверное декодирование может разъехать аудио и текст, особенно при быстрой речи или перекрывающихся голосах.
7. Постобработка
- Добавляет пунктуацию, заглавные буквы и форматирование (числа, даты, валюты).
- Опциональные доменные правки улучшают читаемость и точность.
Влияние на точность: Без постобработки текст может остаться неструктурированным или двусмысленным даже при корректном распознавании на уровне фонем.
Ключевые факторы качества STT
- Качество аудио: Чистые, высококачественные записи критичны.
- Фоновый шум: Музыка, толпа, окружение снижают точность.
- Вариативность дикторов: Акцент, темп и интонация влияют на распознавание.
- Словарь и предметная область: Термины, сленг, редкие слова могут распознаваться неверно.
- Обучение модели: Модели на разнообразных данных устойчивее к акцентам и шуму.
- Сегментация и паузы: Чёткое разделение речи, тишины и нескольких говорящих улучшает ясность транскрипции.
Итого, точность STT определяется не одним компонентом, а взаимодействием качества аудио, предобработки, признаков, моделирования и постобработки.
Заключение
ИИ speech-to-text — многоэтапный конвейер от аудио к тексту. Понимание этапов помогает объяснять ошибки и повышать качество. Сочетая качественное аудио, эффективную предобработку, устойчивое моделирование и аккуратную постобработку, разработчики и пользователи получают более точные и надёжные транскрипции.
Главная мысль: эффективность STT зависит и от технического конвейера, и от качества входа; даже самым продвинутым моделям нужен чистый, хорошо подготовленный звук для лучших результатов.