低延迟语音识别:使用 SayToWords 实现实时语音转文字

Eric King
Author
欢迎来到 SayToWords!
SayToWords 是一个由 AI 驱动的平台,可将语音以极低延迟转换为文本。
它专为需要快速、实时转录且不牺牲准确性的用户而设计。
它专为需要快速、实时转录且不牺牲准确性的用户而设计。
无论你是在转录会议、播客、直播,还是客服通话,低延迟语音识别都能确保文本在音频说出的同时几乎即时显示。
🚀 什么是低延迟语音识别?
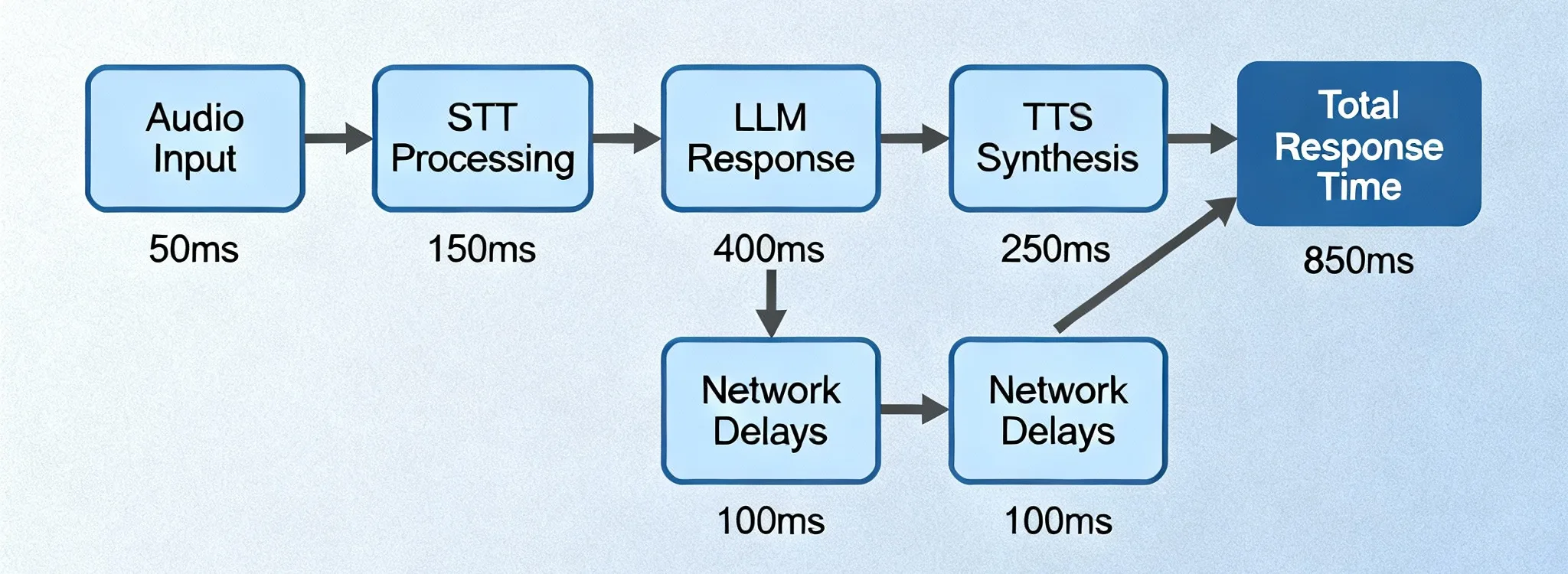
低延迟语音识别是指以最小延迟将语音音频转换为文本——通常可在毫秒级内完成。
从实际应用角度看,它可实现:
- 近乎实时的字幕
- 会议实时字幕
- 即时语音指令反馈
- 快速的 AI 智能笔记
延迟越低,用户体验就越自然、响应越及时。
⏱ 理解语音转文字中的延迟
延迟是以下两者之间的时间差:
一个词被说出时 → 它显示为文本时
- 高延迟会导致字幕滞后并降低可用性
- 低延迟可带来流畅的实时转录
现代 AI 系统的目标是在保持准确率的同时,尽可能缩短这段延迟。
⚡ 为什么低延迟很重要
低延迟语音识别对于以下场景至关重要:
🎙 现场会议与大会
参会者依赖即时字幕来提升可访问性与理解清晰度。
📺 直播与广播
字幕延迟会降低互动度和观众信任。
🤖 语音助手
快速转录让语音交互更自然。
📞 客服支持与呼叫中心
实时转录帮助坐席更快、更智能地响应。
🧠 SayToWords 如何实现低延迟
SayToWords 基于速度优先的 AI 转录流水线构建。
✅ 优化的 AI 模型
我们提供多种针对不同延迟需求设计的转录模型:
- Fastest Model – 超低延迟,适合实时场景
- Balanced Model – 速度快且准确率出色
- Accurate Model – 对长音频或复杂音频提供最高准确率
你可以选择最符合使用场景的模型。
✅ 基于分块的音频处理
音频会以小片段方式处理,使文本能够逐步显示,而不是等待整个文件处理完成后再输出。
这能显著减少用户感知的等待时间。
✅ 预配置语言设置
提前选择语音语言后,SayToWords 可避免额外的语言检测步骤,从而进一步减少处理延迟。
🛠 如何在 SayToWords 上使用低延迟语音识别
📌 第 1 步:上传你的音频或视频
登录后,进入仪表盘并点击 “Transcribe Audio / Video”。
支持的格式包括:
- MP3
- WAV
- M4A
- MP4
- MOV
📌 第 2 步:选择快速转录模型
为了将延迟降到最低:
- 直播或短录音请选择 Fastest Model
- 兼顾实时性与准确率请选择 Balanced Model
📌 第 3 步:设置语言和说话人选项
- 选择语音语言
- 若音频包含多位说话人,请启用 Speaker Recognition
这些设置有助于同时优化速度与准确率。
📌 第 4 步:开始转录
点击 Transcribe,文本将几乎即时出现。
在处理继续进行时,你可以查看、编辑并优化转录内容。
⚖️ 准确率 vs 延迟:如何选择合适模型
不同场景需要不同的权衡:
| Use Case | Recommended Model |
|---|---|
| Live meetings | Fastest |
| Podcasts | Balanced |
| Interviews | Accurate |
| Legal or research | Accurate |
SayToWords 让你能够完全掌控这种平衡。
🌍 常见使用场景
借助 SayToWords 的低延迟语音识别,非常适合:
- 实时字幕与说明字幕
- 实时会议记录
- 流媒体内容转录
- 客服支持监控
- AI 驱动的语音工作流
🔒 可靠、可扩展且易于使用
SayToWords 面向个人和团队打造:
- 安全的文件处理
- 可扩展的基础设施
- 多语言支持
- 基于浏览器,无需安装
🎯 最后总结
低延迟语音识别是现代实时通信的基础。
通过 SayToWords,你将获得:
- ⚡ 快速、低延迟的语音转文字
- 🎯 高质量 AI 转录
- 🌐 多语言支持
- 🧠 智能说话人识别
今天就开始使用 SayToWords,体验无需等待的实时转录。
祝你转录愉快!🎧✍️
