语音活动检测(VAD)

Eric King
Author
语音活动检测(Voice Activity Detection,VAD)是一种信号处理技术,用于自动判断某段音频是否包含人类语音,还是静音或背景噪声。在语音系统中,VAD 作为预处理阶段,在自动语音识别(ASR)、语音翻译或说话人分析等后续步骤之前,将语音区域与非语音区域分开。
1. 什么是语音活动检测?
VAD 是现代语音处理系统的基础组件。它对每个短时音频帧进行二分类:判断该帧包含语音还是非语音(静音、噪声、音乐等)。
核心思路很简单:
音频帧 → VAD 模型 → P(语音)
若概率超过预设阈值,则将该帧判为语音;否则判为非语音。
2. 为什么 VAD 很重要
原始音频信号通常包含:
- 长时间静音
- 背景噪声
- 非语音声音(音乐、点击声、呼吸声等)
若直接将此类音频送入 ASR 模型,会导致:
- 在静音与噪声上浪费计算
- 噪声干扰降低识别准确率
- 分段不稳定与标点错误
- 不必要计算带来的更高处理成本
通过去除非语音片段,VAD 能显著提升下游语音模型的效率与准确率。
3. 典型的 VAD 处理流程
VAD 处理管线通常包括:
- 原始音频 →
- 分帧(10–30 ms)→
- 特征提取 →
- 语音概率估计 →
- 时间平滑 →
- 生成语音片段
3.1 分帧
将信号划分为短且相互重叠的帧(常见为 20 ms),以捕获短时声学特性。分帧在可管理的块上分析音频,同时通过重叠保留时间信息。
3.2 特征提取
VAD 中常用的特征包括:
- 短时能量 — 衡量信号功率
- 过零率 — 反映频率内容
- 谱熵 — 衡量频域随机性
- 对数梅尔滤波器组 — 用于基于神经网络的 VAD,以获得更好表示
这些特征通过不同声学属性帮助区分语音与非语音。
3.3 语音概率估计
模型(基于规则或神经网络)估计每一帧包含语音的可能性,再与阈值比较以做出最终决策。
3.4 时间平滑
将帧级决策按时间规则合并为连续语音片段:
- 当语音概率在阈值之上保持超过最小时长时,开始一个语音片段
- 当静音持续超过预设静音时长时,结束该片段
从而减少因噪声或短暂停顿导致的语音/静音频繁切换。
4. 从帧到语音片段
帧级 VAD 决策需转换为连续语音片段,规则包括:
- 语音起:语音概率在阈值之上持续达到最小时长,片段开始
- 语音止:静音超过预设时长,片段结束
可避免真实语音中短暂噪声或停顿造成的碎片化。
5. 填充与边界调整
为避免截断语音的起止,VAD 系统通常会做填充(padding):
- 在检测到的语音片段前后增加小边距(例如 100–300 ms)
- 提升自然度与识别准确率
- 有助于捕获可能被部分截断的完整词与短语
合适的填充对准确转写至关重要。
6. VAD 算法类型
6.1 基于规则的 VAD
使用手工设计的声学特征与简单决策规则:
- 优点:轻量、快速,适合资源受限环境
- 缺点:对噪声与多变声学条件鲁棒性较差
在可控环境中表现良好,但在真实噪声中较难。
6.2 基于统计模型的 VAD
采用概率模型:
- 高斯混合模型(GMM) — 建模语音与非语音特征的分布
- 隐马尔可夫模型(HMM) — 捕获帧间时间依赖
比纯规则方法更鲁棒,但计算资源需求更高。
6.3 基于神经网络的 VAD(现代主流)
使用深度学习架构:
- CNN / RNN / Transformer
- 在大型含噪数据集上训练
- 在多样环境中高度鲁棒
现代 VAD 示例:
- WebRTC VAD — 广泛用于实时通信
- Silero VAD — 高性能神经网络 VAD,支持多语言
由于准确率与鲁棒性更优,神经网络 VAD 已成为生产系统的标准。
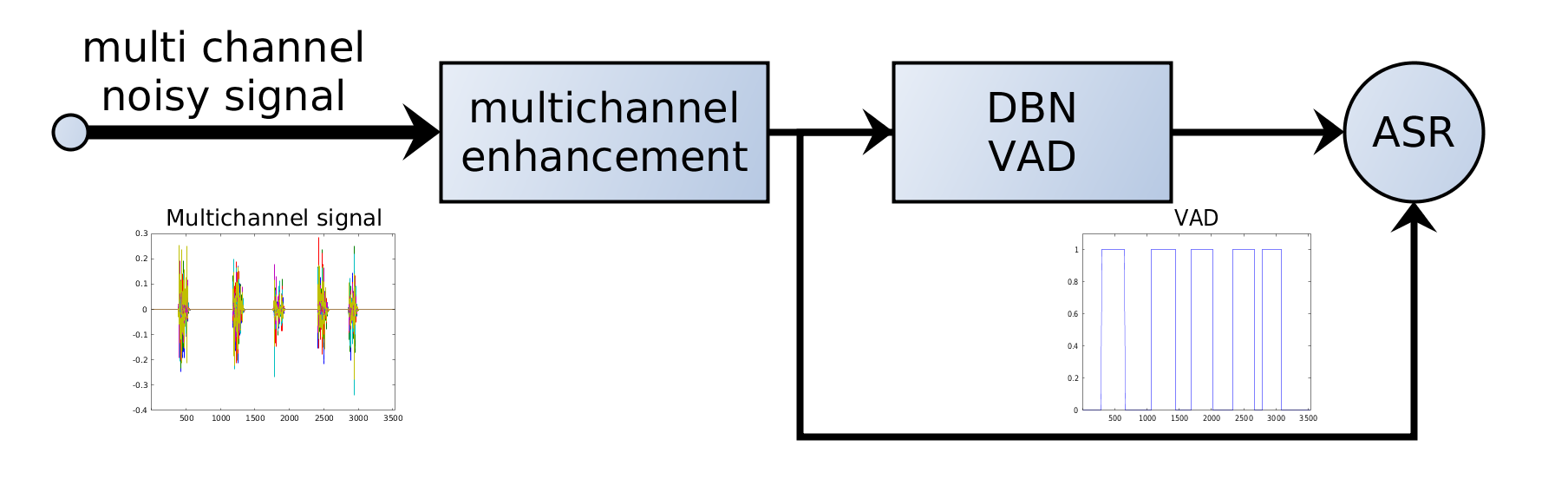
7. ASR 系统中的 VAD
在现代 ASR 流水线中,VAD 通常在识别之前应用:
音频 → VAD → 语音片段 → ASR 模型 → 转写
带来的好处包括:
- 仅处理语音片段,缩短 ASR 推理时间
- 避免噪声干扰,提高解码稳定性
- 对长音频分段,支持并行处理
VAD 如同守门人,只把相关片段送入计算代价高的 ASR 模型。
8. VAD 与时间戳对齐
每个检测到的语音片段保留原始起止时间。转写后,将片段级时间戳映射回全局时间轴,从而保证:
- 字幕时间精确
- 音视频对齐(如视频剪辑)
- **说话人分割(diarization)**与分段
在需要音频与文本精确同步的应用中,时间戳保留非常关键。
9. 实践要点
影响 VAD 行为的主要参数:
- 帧长 — 每帧时长(常见 10–30 ms)
- 语音概率阈值 — 判为语音的最低概率
- 最短语音时长 — 允许的最短语音片段
- 最短静音时长 — 结束片段所需的静音长度
- 填充长度 — 片段前后增加的边距
应按场景调参:
- 会议:更长静音容忍、多人说话
- 播客:语音清晰、背景噪声少
- 呼叫中心:环境嘈杂、音质多变
恰当调参对获得最佳 VAD 性能至关重要。
结语
语音活动检测是语音处理系统的基础组件。通过准确判断何时存在语音,VAD 使 ASR 等下游模型更高效、更准确、更可靠。
在生产级语音系统中,VAD 不是可选项,而是必需品。现代神经网络 VAD 在鲁棒性与准确率上已取得显著进展。随着语音技术演进,VAD 仍将是确保整条处理链路达到最佳性能的关键预处理步骤。
