Wie Sprache-zu-Text funktioniert und was die Genauigkeit beeinflusst
2025-11-27Dokumentation

Eric King
Author
Einleitung
Speech-to-Text (STT), auch automatische Spracherkennung (ASR), wandelt gesprochene Sprache in geschriebenen Text um. Moderne KI-Systeme sind sehr genau – die Qualität der Transkription hängt jedoch von vielen Faktoren im gesamten Ablauf ab. Dieser Artikel erläutert, wie STT funktioniert und welche Elemente die Wirksamkeit beeinflussen.
Speech-to-Text (STT), auch automatische Spracherkennung (ASR), wandelt gesprochene Sprache in geschriebenen Text um. Moderne KI-Systeme sind sehr genau – die Qualität der Transkription hängt jedoch von vielen Faktoren im gesamten Ablauf ab. Dieser Artikel erläutert, wie STT funktioniert und welche Elemente die Wirksamkeit beeinflussen.
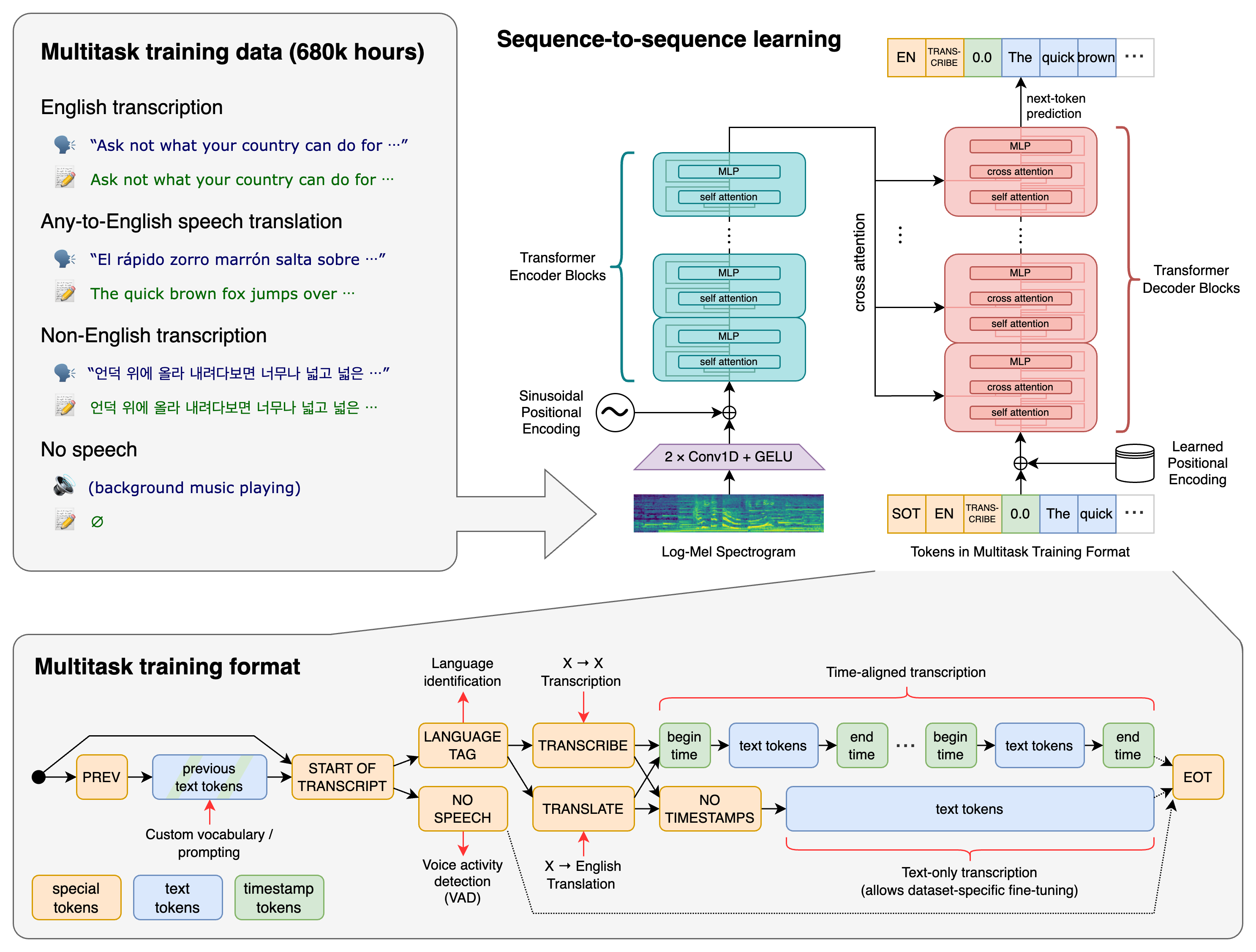
Der STT-Ablauf
Der STT-Prozess lässt sich in mehrere Phasen unterteilen:
Audioeingang → Vorverarbeitung → Merkmalsextraktion → akustische Modellierung → Sprachmodellierung → Decodierung → Nachbearbeitung → Textausgabe
Jede Phase ist entscheidend für die Transkriptionsqualität.
1. Audioeingang
- Quelle: Mikrofone, hochgeladene Aufnahmen oder Live-Streams.
- Qualitätsfaktoren: Klares Audio mit wenig Hintergrundgeräusch verbessert die Erkennung.
- Abtastrate und Format: Höhere Abtastraten (z. B. 16–48 kHz) erhalten Details der Sprache und unterstützen die Merkmalsextraktion.
Einfluss auf die Genauigkeit: Schlechte Aufnahmegeräte oder minderwertige Dateien verringern die Signalqualität und führen zu Fehlern in den folgenden Schritten.
2. Vorverarbeitung
- Rauschunterdrückung: Entfernt Störgeräusche, die das Modell verwirren können.
- Normalisierung: Gleicht die Lautstärke über die Aufnahme hinweg aus.
- Segmentierung (Framing): Teilt Audio in kurze Fenster (typisch 20–40 ms) für die sequenzielle Verarbeitung.
Einfluss auf die Genauigkeit: Unzureichende Vorverarbeitung lässt Rauschen, Hall oder ungleichmäßige Lautstärke das Signal verzerren und senkt die Erkennungsqualität.
3. Merkmalsextraktion
- Wandelt Audiofenster in numerische Darstellungen (Merkmale) für das Modell um.
- Häufige Merkmale:
- MFCC (Mel-Frequency Cepstral Coefficients): Erfassen wichtige Frequenzanteile.
- Spektrogramme: Zeigen die Energieverteilung über Zeit und Frequenz.
- Optionale Merkmale: Tonhöhe, Energie oder Delta-Koeffizienten.
Einfluss auf die Genauigkeit: Wenn Merkmale die Sprachmerkmale schlecht abbilden, kann das akustische Modell Phoneme falsch deuten – besonders bei schneller oder akzentuierter Sprache.
4. Akustische Modellierung
- Ordnet Merkmale Phonemen oder Zeichen zu.
- Moderne Architekturen:
- RNN/LSTM/GRU: Erfassen zeitliche Abfolgen.
- CNN: Erfassen lokale Frequenzmuster.
- Transformer: Modellieren weitreichenden Kontext in der Sprache.
Einfluss auf die Genauigkeit: Modellgröße, Vielfalt der Trainingsdaten und Rauschrobustheit bestimmen, wie gut Aussprachevariationen und Akzente erkannt werden.
5. Sprachmodellierung
- Sagt Wortfolgen aus Kontext, Grammatik und Vokabular voraus.
- Hilft bei Homophonen und löst mehrdeutige Phoneme auf.
Einfluss auf die Genauigkeit: Schwache oder begrenzte Sprachmodelle können grammatikalisch falschen oder unsinnigen Text erzeugen, selbst wenn die Phoneme stimmen.
6. Decodierung
- Führt die Ausgaben von akustischem und Sprachmodell zur endgültigen Textfolge zusammen.
- Verfahren u. a.:
- CTC (Connectionist Temporal Classification): Richtet Audiofenster und vorhergesagten Text aus.
- Beam Search: Wählt wahrscheinliche Wortsequenzen.
Einfluss auf die Genauigkeit: Fehlerhafte Decodierung kann Audio und Text versetzen – besonders bei schneller Sprache oder überlappenden Stimmen.
7. Nachbearbeitung
- Fügt Interpunktion, Großschreibung und Formatierung hinzu (Zahlen, Daten, Währungen).
- Optionale domänenspezifische Korrekturen verbessern Lesbarkeit und Genauigkeit.
Einfluss auf die Genauigkeit: Ohne Nachbearbeitung wirkt der Text unstrukturiert oder mehrdeutig, selbst wenn die Phonemerkennung stimmt.
Zentrale Faktoren für die STT-Leistung
- Audioqualität: Klare, hochwertige Aufnahmen sind entscheidend.
- Hintergrundgeräusch: Musik, Stimmengewirr oder Umgebungslärm senken die Genauigkeit.
- Sprechervariation: Akzent, Tempo und Intonation beeinflussen die Erkennung.
- Vokabular und Domäne: Fachbegriffe, Slang oder seltene Wörter können falsch erkannt werden.
- Modelltraining: Auf vielfältigen Daten trainierte Modelle sind robuster gegen Akzente und Rauschen.
- Segmentierung und Stille: Klare Trennung von Sprache, Stille und überlappenden Sprechern verbessert die Lesbarkeit der Transkription.
Kurz: Die STT-Genauigkeit hängt nicht von einem einzelnen Baustein ab, sondern vom Zusammenspiel von Audioqualität, Vorverarbeitung, Merkmalen, Modellierung und Nachbearbeitung.
Fazit
Speech-to-Text-KI ist eine mehrstufige Pipeline von Audio zu Text. Wer den Ablauf kennt, versteht besser, warum Fehler entstehen und wie man die Leistung verbessert. Mit hochwertigem Audio, solider Vorverarbeitung, robusten Modellen und durchdachter Nachbearbeitung lassen sich genauere und zuverlässigere Transkripte erzielen.
Kernaussage: Die STT-Wirksamkeit hängt sowohl von der technischen Pipeline als auch von der Eingabequalität ab – selbst die fortschrittlichsten Modelle brauchen sauberes, gut strukturiertes Audio für beste Ergebnisse.