Cómo funciona la conversión de voz a texto y qué afecta a su precisión
2025-11-27Documentación

Eric King
Author
Introducción
La conversión de voz a texto (STT), también conocida como reconocimiento automático del habla (ASR), transforma el lenguaje hablado en texto escrito. Los sistemas de IA actuales son muy precisos, pero la calidad de la transcripción depende de múltiples factores a lo largo del flujo. Este artículo se centra en cómo funciona el STT y en los elementos clave que inciden en su eficacia.
La conversión de voz a texto (STT), también conocida como reconocimiento automático del habla (ASR), transforma el lenguaje hablado en texto escrito. Los sistemas de IA actuales son muy precisos, pero la calidad de la transcripción depende de múltiples factores a lo largo del flujo. Este artículo se centra en cómo funciona el STT y en los elementos clave que inciden en su eficacia.
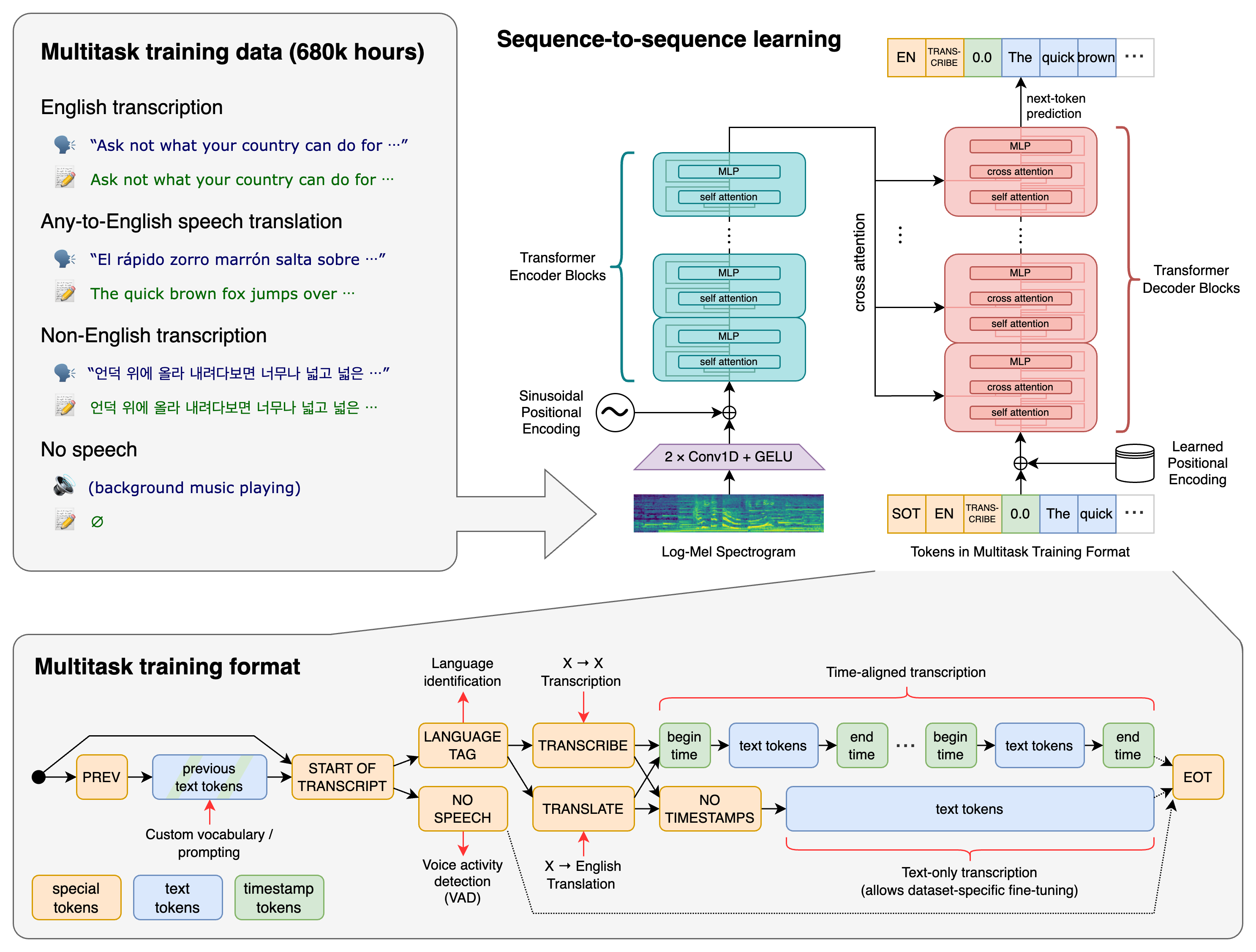
El flujo de trabajo del STT
El proceso STT puede dividirse en varias etapas:
Entrada de audio → Preprocesamiento → Extracción de características → Modelado acústico → Modelado del lenguaje → Decodificación → Postprocesamiento → Salida de texto
Cada etapa es importante para la calidad de la transcripción.
1. Entrada de audio
- Origen: Micrófonos, grabaciones subidas o transmisiones en vivo.
- Factores de calidad: Un audio claro con poco ruido de fondo mejora el reconocimiento.
- Frecuencia de muestreo y formato: Tasas más altas (p. ej., 16–48 kHz) conservan detalles del habla y mejoran la extracción de características.
Impacto en la precisión: Dispositivos de grabación deficientes o archivos de baja calidad reducen la fidelidad del sonido y provocan errores en etapas posteriores.
2. Preprocesamiento
- Reducción de ruido: Elimina el ruido de fondo que puede confundir al modelo.
- Normalización: Mantiene niveles de volumen coherentes en toda la grabación.
- Segmentación (encuadre): Divide el audio en ventanas cortas (habitualmente 20–40 ms) para procesarlas en secuencia.
Impacto en la precisión: Un preprocesamiento insuficiente deja que el ruido, el eco o el volumen irregular distorsionen la señal y baje la calidad del reconocimiento.
3. Extracción de características
- Convierte las ventanas de audio en representaciones numéricas (características) para el modelo.
- Características habituales:
- MFCC (coeficientes cepstrales en escala Mel): Capturan componentes frecuenciales importantes.
- Espectrogramas: Muestran la distribución de energía en el tiempo y la frecuencia.
- Características opcionales: tono, energía o coeficientes delta.
Impacto en la precisión: Si las características no reflejan bien el habla, el modelo acústico puede malinterpretar fonemas, sobre todo con habla rápida o con acento.
4. Modelado acústico
- Asigna características a fonemas o caracteres.
- Modelos modernos:
- RNN/LSTM/GRU: Capturan secuencias temporales.
- CNN: Detectan patrones locales en frecuencia.
- Transformers: Modelan contexto de largo alcance en el habla.
Impacto en la precisión: El tamaño del modelo, la diversidad de los datos de entrenamiento y la robustez al ruido determinan cómo se reconocen variaciones de pronunciación y acento.
5. Modelado del lenguaje
- Predice secuencias de palabras según contexto, gramática y vocabulario.
- Ayuda a distinguir homófonos y resuelve fonemas ambiguos.
Impacto en la precisión: Modelos de lenguaje débiles o limitados pueden producir frases gramaticalmente incorrectas o sin sentido aunque los fonemas se reconozcan bien.
6. Decodificación
- Integra las salidas del modelo acústico y del modelo de lenguaje para generar el texto final.
- Técnicas:
- CTC (Connectionist Temporal Classification): Alinea ventanas de audio con el texto predicho.
- Búsqueda en haz (beam search): Elige secuencias de palabras más probables.
Impacto en la precisión: Una decodificación incorrecta puede desalinear audio y texto, especialmente con habla rápida o voces superpuestas.
7. Postprocesamiento
- Añade puntuación, mayúsculas y formato (números, fechas, monedas).
- Correcciones opcionales por dominio mejoran legibilidad y precisión.
Impacto en la precisión: Sin postprocesamiento, el texto puede quedar poco estructurado o ambiguo aunque el reconocimiento fonético sea correcto.
Factores clave del rendimiento del STT
- Calidad del audio: Grabaciones claras y fieles son fundamentales.
- Ruido de fondo: Música, multitudes o sonidos ambientales reducen la precisión.
- Variabilidad del hablante: Acento, velocidad e entonación influyen.
- Vocabulario y dominio: Términos técnicos, jerga o palabras poco frecuentes pueden malinterpretarse.
- Entrenamiento del modelo: Los modelos entrenados con datos diversos son más robustos ante acentos y ruido.
- Segmentación y silencios: Separar bien el habla del silencio o de varios hablantes mejora la claridad de la transcripción.
En resumen, la precisión del STT no la determina un solo componente, sino la interacción entre calidad de audio, preprocesamiento, extracción de características, modelado y postprocesamiento.
Conclusión
La IA de voz a texto es una canalización por etapas que transforma audio en texto. Entender el flujo ayuda a ver por qué aparecen errores y cómo optimizar el rendimiento. Priorizando audio de alta calidad, preprocesamiento eficaz, modelado robusto y postprocesamiento cuidadoso, desarrolladores y usuarios pueden lograr transcripciones más precisas y fiables.
Idea clave: La eficacia del STT depende tanto del pipeline técnico como de la calidad de la entrada; incluso los modelos más avanzados necesitan audio limpio y bien estructurado para dar lo mejor de sí.