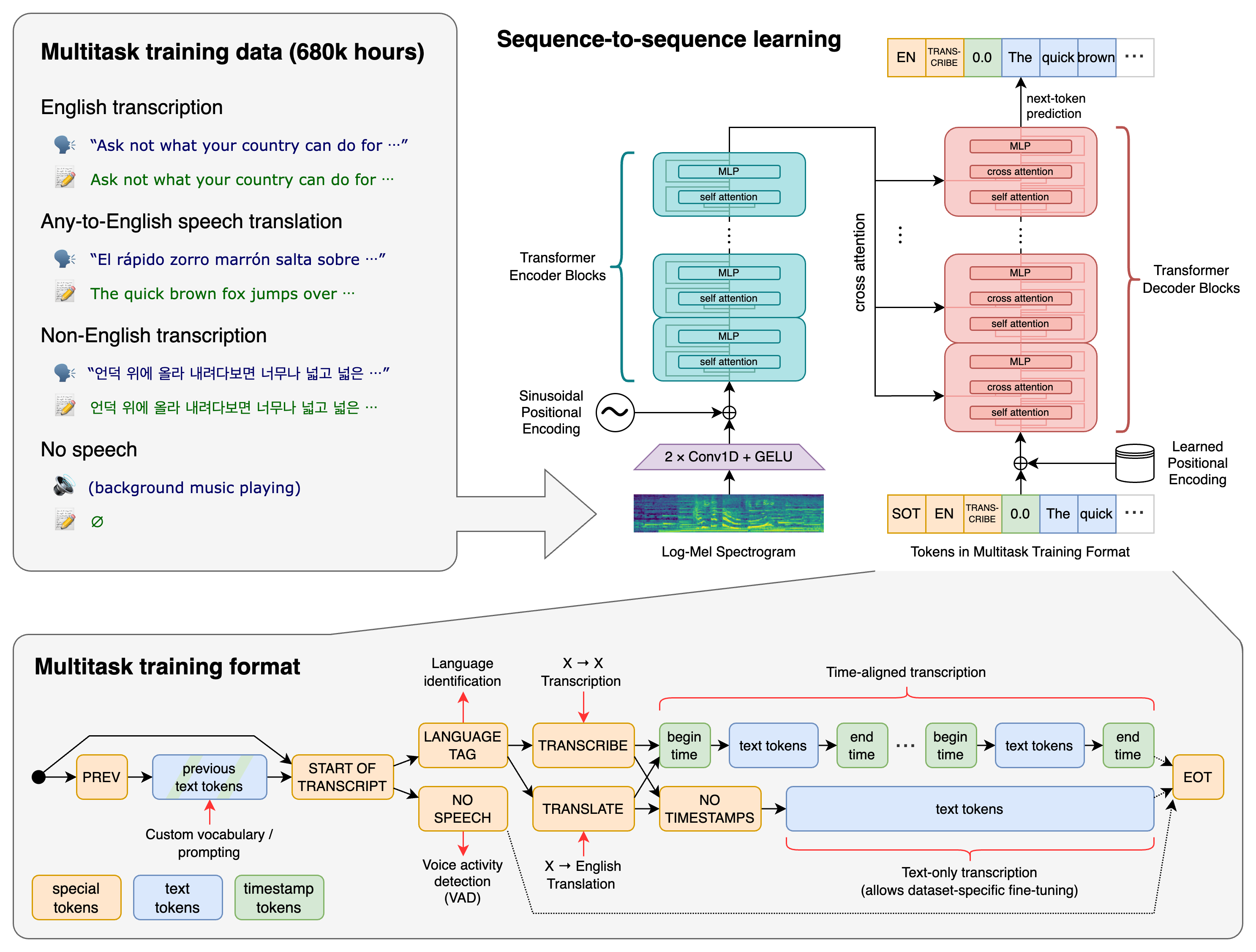
Fonctionnement de la reconnaissance vocale (speech-to-text) et facteurs de précision
2025-11-27Documentation

Eric King
Author
Introduction
La conversion de la parole en texte (STT), ou reconnaissance automatique de la parole (ASR), transforme le langage oral en texte écrit. Les systèmes d’IA modernes sont très précis, mais la qualité de la transcription dépend de nombreux facteurs tout au long du traitement. Cet article présente le fonctionnement du STT et les éléments clés qui influencent son efficacité.
La conversion de la parole en texte (STT), ou reconnaissance automatique de la parole (ASR), transforme le langage oral en texte écrit. Les systèmes d’IA modernes sont très précis, mais la qualité de la transcription dépend de nombreux facteurs tout au long du traitement. Cet article présente le fonctionnement du STT et les éléments clés qui influencent son efficacité.
Le flux STT
Le processus STT peut se découper en plusieurs étapes :
Entrée audio → Prétraitement → Extraction de caractéristiques → Modélisation acoustique → Modélisation du langage → Décodage → Post-traitement → Sortie texte
Chaque étape joue un rôle important pour la qualité de la transcription.
1. Entrée audio
- Source : Microphones, enregistrements importés ou flux en direct.
- Facteurs de qualité : Un audio clair avec peu de bruit de fond améliore la reconnaissance.
- Fréquence d’échantillonnage et format : Des taux plus élevés (p. ex. 16–48 kHz) préservent les détails de la parole et facilitent l’extraction de caractéristiques.
Impact sur la précision : Des appareils d’enregistrement médiocres ou des fichiers de faible qualité réduisent la fidélité du signal et entraînent des erreurs en aval.
2. Prétraitement
- Réduction du bruit : Supprime le bruit de fond susceptible de tromper le modèle.
- Normalisation : Harmonise le niveau sonore sur tout l’enregistrement.
- Segmentation (fenêtrage) : Découpe l’audio en courtes fenêtres (souvent 20–40 ms) pour un traitement séquentiel.
Impact sur la précision : Un prétraitement insuffisant laisse le bruit, la réverbération ou des volumes irréguliers déformer le signal et dégrade la reconnaissance.
3. Extraction de caractéristiques
- Convertit les fenêtres audio en représentations numériques (caractéristiques) pour le modèle.
- Caractéristiques courantes :
- MFCC (coefficients cepstraux en échelle Mel) : Captent les composantes fréquentielles importantes.
- Spectrogrammes : Représentent la distribution d’énergie dans le temps et la fréquence.
- Caractéristiques optionnelles : hauteur, énergie ou coefficients delta.
Impact sur la précision : Si les caractéristiques ne reflètent pas bien la parole, le modèle acoustique peut mal interpréter les phonèmes, surtout avec une parole rapide ou accentuée.
4. Modélisation acoustique
- Associe les caractéristiques aux phonèmes ou caractères.
- Architectures modernes :
- RNN/LSTM/GRU : Capturent les séquences temporelles.
- CNN : Détectent des motifs fréquentiels locaux.
- Transformers : Modélisent le contexte à longue portée dans la parole.
Impact sur la précision : La taille du modèle, la diversité des données d’entraînement et la robustesse au bruit déterminent la qualité de reconnaissance des variations de prononciation et d’accent.
5. Modélisation du langage
- Prédit des séquences de mots selon le contexte, la grammaire et le vocabulaire.
- Aide à distinguer les homophones et à lever l’ambiguïté des phonèmes.
Impact sur la précision : Des modèles de langage faibles ou limités peuvent produire des phrases incorrectes grammaticalement ou absurdes même si les phonèmes sont bien reconnus.
6. Décodage
- Combine les sorties du modèle acoustique et du modèle de langage pour produire le texte final.
- Techniques :
- CTC (Connectionist Temporal Classification) : Aligne les fenêtres audio avec le texte prédit.
- Beam search : Sélectionne les séquences de mots les plus probables.
Impact sur la précision : Un décodage inadapté peut désaligner l’audio et le texte, notamment avec une parole rapide ou des voix qui se chevauchent.
7. Post-traitement
- Ajoute ponctuation, majuscules et mise en forme (nombres, dates, devises).
- Des corrections optionnelles spécifiques au domaine améliorent lisibilité et précision.
Impact sur la précision : Sans post-traitement, le texte peut rester peu structuré ou ambigu même si la reconnaissance au niveau phonème est correcte.
Facteurs clés des performances STT
- Qualité audio : Des enregistrements clairs et fidèles sont essentiels.
- Bruit de fond : Musique, foule ou bruit ambiant réduisent la précision.
- Variabilité des locuteurs : Accent, débit et intonation influencent la reconnaissance.
- Vocabulaire et domaine : Termes techniques, argot ou mots rares peuvent être mal interprétés.
- Entraînement du modèle : Les modèles entraînés sur des jeux de données variés sont plus robustes aux accents et au bruit.
- Segmentation et silences : Bien séparer la parole du silence ou de plusieurs locuteurs améliore la clarté de la transcription.
En résumé, la précision du STT ne dépend pas d’un seul composant, mais de l’interaction entre qualité audio, prétraitement, extraction de caractéristiques, modélisation et post-traitement.
Conclusion
L’IA speech-to-text est un pipeline multi-étapes qui transforme l’audio en texte. Comprendre le flux permet d’expliquer les erreurs et d’optimiser les performances. En misant sur un audio de haute qualité, un prétraitement efficace, une modélisation robuste et un post-traitement soigné, développeurs et utilisateurs obtiennent des transcriptions plus précises et fiables.
Point clé : L’efficacité du STT repose à la fois sur le pipeline technique et sur la qualité de l’entrée ; même les modèles les plus avancés ont besoin d’un audio propre et bien structuré pour fonctionner au mieux.