Como funciona a conversão de fala em texto e o que afeta a precisão
2025-11-27Documentação

Eric King
Author
Introdução
A conversão de fala em texto (STT), também chamada de reconhecimento automático de fala (ASR), transforma linguagem falada em texto escrito. Os sistemas de IA modernos são muito precisos, mas a qualidade da transcrição depende de vários fatores ao longo do fluxo. Este artigo foca em como o STT funciona e nos elementos-chave que afetam a sua eficácia.
A conversão de fala em texto (STT), também chamada de reconhecimento automático de fala (ASR), transforma linguagem falada em texto escrito. Os sistemas de IA modernos são muito precisos, mas a qualidade da transcrição depende de vários fatores ao longo do fluxo. Este artigo foca em como o STT funciona e nos elementos-chave que afetam a sua eficácia.
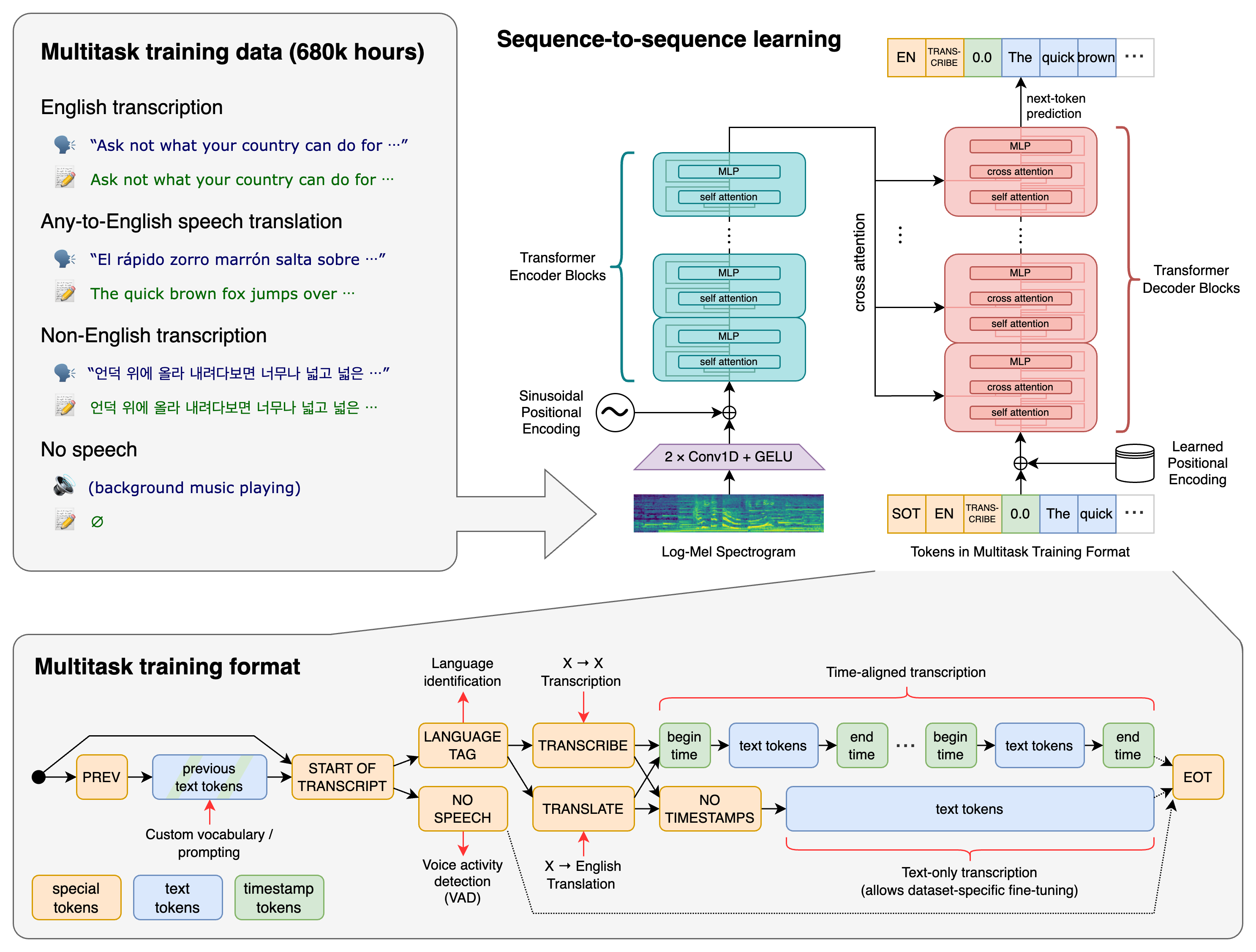
O fluxo do STT
O processo STT pode dividir-se em várias etapas:
Entrada de áudio → Pré-processamento → Extração de características → Modelagem acústica → Modelagem de linguagem → Descodificação → Pós-processamento → Saída de texto
Cada etapa é importante para a qualidade da transcrição.
1. Entrada de áudio
- Fonte: Microfones, gravações carregadas ou transmissões em direto.
- Fatores de qualidade: Áudio claro com pouco ruído de fundo melhora o reconhecimento.
- Taxa de amostragem e formato: Taxas mais altas (p.ex. 16–48 kHz) preservam detalhes da fala e ajudam na extração de características.
Impacto na precisão: Gravadores fracos ou ficheiros de baixa qualidade reduzem a fidelidade do som e causam erros nas etapas seguintes.
2. Pré-processamento
- Redução de ruído: Remove ruído de fundo que pode confundir o modelo.
- Normalização: Mantém níveis de volume consistentes na gravação.
- Segmentação (enquadramento): Divide o áudio em pequenas janelas (normalmente 20–40 ms) para processamento sequencial.
Impacto na precisão: Pré-processamento insuficiente deixa eco, ruído ou volume irregular distorcer o sinal e baixa a qualidade do reconhecimento.
3. Extração de características
- Converte janelas de áudio em representações numéricas (características) para o modelo.
- Características comuns:
- MFCC (coeficientes cepstrais em escala Mel): Capturam componentes de frequência importantes.
- Espectrogramas: Mostram a distribuição de energia no tempo e na frequência.
- Características opcionais: altura, energia ou coeficientes delta.
Impacto na precisão: Se as características não representam bem a fala, o modelo acústico pode interpretar mal fonemas, sobretudo com fala rápida ou sotaque.
4. Modelagem acústica
- Mapeia características para fonemas ou caracteres.
- Modelos modernos:
- RNN/LSTM/GRU: Capturam sequências temporais.
- CNN: Detetam padrões locais de frequência.
- Transformers: Modelam contexto de longo alcance na fala.
Impacto na precisão: Tamanho do modelo, diversidade dos dados de treino e robustez ao ruído determinam o reconhecimento de variações de pronúncia e sotaque.
5. Modelagem de linguagem
- Prevê sequências de palavras com base em contexto, gramática e vocabulário.
- Ajuda com homófonos e resolve fonemas ambíguos.
Impacto na precisão: Modelos de linguagem fracos ou limitados podem produzir frases gramaticalmente incorretas ou sem sentido mesmo com fonemas corretos.
6. Descodificação
- Integra as saídas do modelo acústico e do modelo de linguagem para gerar o texto final.
- Técnicas:
- CTC (Connectionist Temporal Classification): Alinha janelas de áudio com o texto previsto.
- Beam search: Escolhe sequências de palavras mais prováveis.
Impacto na precisão: Descodificação incorreta pode desalinhar áudio e texto, especialmente com fala rápida ou vozes sobrepostas.
7. Pós-processamento
- Adiciona pontuação, maiúsculas e formatação (números, datas, moedas).
- Correcções opcionais por domínio melhoram legibilidade e precisão.
Impacto na precisão: Sem pós-processamento, o texto pode ficar pouco estruturado ou ambíguo mesmo com reconhecimento fonético correto.
Fatores-chave do desempenho do STT
- Qualidade do áudio: Gravações claras e fiáveis são essenciais.
- Ruído de fundo: Música, multidões ou ambiente reduzem a precisão.
- Variabilidade do falante: Sotaque, velocidade e entoação influenciam o reconhecimento.
- Vocabulário e domínio: Termos técnicos, gírias ou palavras raras podem ser mal interpretados.
- Treino do modelo: Modelos treinados com dados diversos são mais robustos a sotaques e ruído.
- Segmentação e silêncios: Separar bem fala, silêncio e vários falantes melhora a clareza da transcrição.
Em resumo, a precisão do STT não é determinada por um único componente, mas pela interação entre qualidade de áudio, pré-processamento, extração de características, modelagem e pós-processamento.
Conclusão
A IA de fala para texto é um pipeline em várias etapas que transforma áudio em texto. Compreender o fluxo ajuda a identificar erros e a otimizar o desempenho. Com áudio de alta qualidade, pré-processamento eficaz, modelagem robusta e pós-processamento cuidadoso, programadores e utilizadores obtêm transcrições mais precisas e fiáveis.
Ideia-chave: A eficácia do STT depende tanto do pipeline técnico como da qualidade da entrada; mesmo os modelos mais avançados precisam de áudio limpo e bem estruturado para o melhor desempenho.